Introduction
In this article, I want to tell you about SQL Server 2000 lock modes. SQL Server 2000 supports the following lock modes:
Shared (S)
Update (U)
Exclusive (X)
Intent
intent shared (IS)
intent exclusive (IX)
shared with intent exclusive (SIX)
intent update (IU)
update intent exclusive (UIX)
shared intent update (SIU)
Schema
schema modification (Sch-M)
schema stability (Sch-S)
Bulk Update (BU)
Key-Range
Shared Key-Range and Shared Resource lock (RangeS_S)
Shared Key-Range and Update Resource lock (RangeS_U)
Insert Key-Range and Null Resource lock (RangeI_N)
Exclusive Key-Range and Exclusive Resource lock (RangeX_X)
Conversion Locks (RangeI_S, RangeI_U, RangeI_X, RangeX_S, RangeX_U)
Shared locks
Shared (S) locks are used for operations that read data, such as a SELECT statement. During Shared (S) locks use, concurrent transactions can read (SELECT) a resource, but cannot modify the data while Shared (S) locks exist on the resource. If you do not use the HOLDLOCK locking hint and your transaction isolation level is not set to REPEATABLE READ or SERIALIZABLE, the Shared (S) locks on a resource are released as soon as the data has been read. If you use the HOLDLOCK locking hint or your transaction isolation level is set to REPEATABLE READ or SERIALIZABLE, the Shared (S) locks on a resource will be held until the end of the transaction.
By the way, when you select a database in the Enterprise Manager and then click Tables, the Shared (S) lock will be placed on this database, but you can insert/delete/update rows in the tables in this database.
Update locks
Update (U) locks are used when SQL Server intends to modify a row or page, and later promotes the update page lock to an exclusive lock before actually making the changes. The Update (U) locks are used to prevent a deadlock. For example, if two transactions intend to update the same row, each of these transactions will set the shared lock on this resource and then try to set the exclusive lock. Without Update (U) locks, each transaction will wait for the other transaction to release its shared-mode lock, and a deadlock will occur.
To prevent a potential deadlock, the first transaction that tries to update the row will set the Update (U) lock on this row. Because only one transaction can obtain an Update (U) lock to a resource at a time, the second transaction will wait until the first transaction converts the update lock to an exclusive lock and releases the locked resource.
Exclusive locks
Exclusive (X) locks are used for data modification operations, such as UPDATE, INSERT, or DELETE.
Other transactions cannot read or modify data locked with an Exclusive (X) lock. If a Shared (S) exists, other transactions cannot acquire an Exclusive (X) lock.
Intent locks
Intent locks are used when SQL Server wants to acquire a shared lock or exclusive lock on some of the resources lower down in the hierarchy.
Intent locks include:
intent shared (IS)
intent exclusive (IX)
shared with intent exclusive (SIX)
intent update (IU)
update intent exclusive (UIX)
shared intent update (SIU)
Intent shared (IS) locks are used to indicate the intention of a transaction to read some resources lower in the hierarchy by placing Shared (S) locks on those individual resources.
Intent exclusive (IX) locks are used to indicate the intention of a transaction to modify some resources lower in the hierarchy by placing Exclusive (X) locks on those individual resources.
Shared with intent exclusive (SIX) locks are used to indicate the intention of the transaction to read all of the resources lower in the hierarchy and modify some resources lower in the hierarchy by placing Intent exclusive (IX) locks on those individual resources.
Intent update (IU) locks are used to indicate the intention to place Update (U) locks on some subordinate resource in the lock hierarchy.
Update intent exclusive (UIX) locks are used to indicate an Update (U) lock hold on a resource with the intent of acquiring Exclusive (X) locks on subordinate resources in the lock hierarchy.
Shared intent update (SIU) locks are used to indicate shared access to a resource with the intent of acquiring Update (U) locks on subordinate resources in the lock hierarchy.
Schema locks
Schema locks are used when an operation dependent on the schema of a table is executing.
Schema locks include:
schema modification (Sch-M)
schema stability (Sch-S)
Schema modification (Sch-M) locks are used when a table data definition language (DDL) operation is being performed.
Schema stability (Sch-S) locks are used when compiling queries. This lock does not block any transactional locks, but when the Schema stability (Sch-S) lock is used, the DDL operations cannot be performed on the table.
Bulk Update locks
Bulk Update (BU) locks are used during bulk copying of data into a table when one of the following conditions exist:
TABLOCK hint is specified
table lock on bulk load table option is set using sp_tableoption
The bulk update table-level lock allows processes to bulk copy data concurrently into the same table while preventing other processes that are not bulk copying data from accessing the table.
Key-Range locks
Key-Range locks are used by SQL Server to prevent phantom insertions or deletions into a set of records accessed by a transaction. Key-Range locks are used on behalf of transactions operating at the serializable isolation level.
Shared Key-Range and Shared Resource (RangeS_S) locks are used to indicate a serializable range scan.
Shared Key-Range and Update Resource (RangeS_U) locks are used to indicate a serializable update scan.
Insert Key-Range and Null Resource (RangeI_N) locks are used to test ranges before inserting a new key into an index.
Exclusive Key-Range and Exclusive Resource (RangeX_X) locks are used when updating a key in a range.
There are also Key-Range conversion locks. Key-Range conversion locks include:
RangeI_S
RangeI_U
RangeI_X
RangeX_S
RangeX_U
Key-Range conversion locks are created when a Key-Range lock overlaps another lock.
RangeI_S locks are used when RangeI_N lock overlap Shared (S) lock.
RangeI_U locks are used when RangeI_N lock overlap Update (U) lock.
RangeI_X locks are used when RangeI_N lock overlap Exclusive (X) lock.
RangeX_S locks are used when RangeI_N lock overlap RangeS_S lock.
RangeX_U locks are used when RangeI_N lock overlap RangeS_U lock.
Key-Range conversion locks are rarely used and can be observed for a short period of time under complex circumstances.
Lock Modes Compatibility
Because IU, UIX and SIU are undocumented Intent locks and Key-Range conversion locks are rarely used and can be observed for a short period of time under complex circumstances, the Lock Modes Compatibility table does not contain these lock modes.
Thursday, April 27, 2006
Transaction Log Guidelines
Every SQL Server database has at least two files associated with it: one data file that houses the actual data and one transaction log file. The transaction log is a fundamental component of a database management system. All changes to application data in the database are recorded serially in the transaction log. Using this information, the DBMS can track which transaction made which changes to SQL Server data.
The Basics of LoggingThe CREATE DATABASE statement is used to create a Microsoft SQL Server database. The LOG ON clause is used to identify the transaction log file for the database to be created. Once created, data is stored in the database file, and a record of the modifications to that data is recorded in the transaction log file.
As database modifications are made, the transaction log for the database will grow. Since most database changes are logged, you will need to actively monitor the size of the transaction log files because if the data is constantly changing, the log will be continuously growing.
At each checkpoint, Microsoft SQL Server will guarantee that all log records and all modified database pages are written safely to disk. Transaction log files are used by Microsoft SQL Server during database recovery operations to commit completed transactions and rollback uncompleted transactions. Information recorded on the transaction log includes:
the beginning time of each transaction
the actual changes made to the data and enough information to undo the modifications made during each transaction (accomplished using before and after images of the data)
the allocation and deallocation of database pages
the actual commit or rollback of each transaction
Using this data, Microsoft SQL Server can accomplish data integrity operations to ensure consistent data is maintained in the database. The transaction log is used when SQL Server is restarted, when transactions are rolled back, and to restore the database to the state prior to the transaction.
When SQL Server is restarted, each database goes through a recovery process. SQL Server checks to determine which transactions must be rolled forward. This occurs for transactions where it is unknown if all the modifications were actually written from the cache to disk. Because a checkpoint forces all modified pages to disk, it represents the point at which the startup recovery must start rolling transactions forward. Because all pages modified before the checkpoint are guaranteed to be on disk, there is no need to roll forward anything done before the checkpoint.
When a transaction is rolled back SQL Server copies before images to the database for every modification made since the BEGIN TRANSACTION.
During a recovery scenario you can use the transaction log to restore a database. This causes a roll forward of the transaction log. During a roll forward SQL Server will copy after images of each modification to the database. Using the logged data SQL Server ensures that each modification is applied in the same order that it originally occurred.
You can see where the transaction log is a useful item to have around in case of database errors, transaction errors, and to ensure data integrity.
Some Operations Are Not Always LoggedMicrosoft SQL Server avoids logging in certain situations to avoid “out of space” conditions caused by rapid growth in transaction log files.
For some large operations, such as CREATE INDEX, Microsoft SQL Server will not log every new page. Instead, SQL Server records enough information to determine that a CREATE INDEX happened, so that it can either be recreated for a roll forward, or removed during a roll back.
Additionally, if the select into/bulkcopy database option is set to TRUE, Microsoft SQL Server will not record the following operations in the transaction log: bulk load operations, SELECT INTO statements, and WRITETEXT and UPDATETEXT statements. Because these operations are not recorded in the transaction log, SQL Server can not use the restore operation on the transaction log to recover these operations. Since SQL Server has no knowledge of the operations occurring, it can not recover the data.
If one of these operations occurs when the select into/bulkcopy option is TRUE, be sure to backup the database so that the changes made be these operations are preserved if a subsequent restore is required.
Transaction Log BackupsTo ensure an efficient and effective backup and recovery strategy for your Microsoft SQL Server databases, you will need to implement a periodic transaction log backups. A transaction log backup is created using the BACKUP LOG command. A database can be restored to any point in time contained within the sequence of transaction logs you have backed up, up to the point of failure. If you do not backup your transaction logs before truncating them, you will only be able to restore your database to the last database backup you have created.
When Microsoft SQL Server finishes backing up the transaction log, it truncates the inactive portion of the transaction log. This frees up space on the transaction log. SQL Server can reuse this truncated space instead of causing the transaction log to continuously grow and consume more space. The active portion of the transaction log contains transactions that are still running and have not completed yet.
Microsoft SQL Server will try to take a checkpoint whenever the transaction log becomes 70 percent full, if a log full error occurs, and when SQL Server is shut down (unless using the NOWAIT option) it will take a checkpoint for each database.
The transaction log should not be backed up if the truncate log on checkpoint database option is set to TRUE. If you specify truncate log on checkpoint to be true, Microsoft SQL Server will clear out inactive transaction log entries at every checkpoint. This option essentially tells SQL Server that you will not be using the transaction log for restore operations. The transaction log is still required to roll back transactions and for SQL Server to determine how to recover databases when it is restarted. Use this option only for systems where it is okay for you to lose transactions during the course of a day, because you will only be able to restore your database back to the last backup that was taken. Applications of this nature are very rare in most production environments.
If a transaction log has been truncated (except by a BACKUP LOG) you should not backup that log until you take a database backup or differential database backup. A differential database backup will backup only data that has changed since the last full database backup.
You should also avoid backing up transaction logs any nonlogged operations have occurred in since the last database backup was created. Create a database or differential database backup instead.
And finally, if any files are added or deleted from the database, a transaction log backup should not be taken. Instead, you should create a full database backup.
Changing Database OptionsThe truncate log on checkpoint option can be changed at the database level. Use the system procedure named sp_dboption to change the configuration settings for a database. For example:
exec sp_dboption 'pubs', 'trunc. log on chkpt.', 'false'This will change the truncate log on checkpoint option to false for the pubs database. To see a list of all current database options set for a database, simply issue the system procedure without additional parameters, for example:
exec sp_dboption pubsYou can also use Enterprise Manager to set database options. When a database is first created, most of its options will be set to false. In the desktop edition of Microsoft SQL Server, however, the truncate log on checkpoint database option is set to true. This may not be a problem depending on the recovery requirements of the data stored in your desktop SQL Server databases.
You might also consider setting truncate log on checkpoint to TRUE during an application development cycle. Usually, it is not important to save every test transaction that is attempted while an application is in development.
ConclusionThis has been a brief introduction to using transaction logs with Microsoft SQL Server. The topic of database backup and recovery is complex and we have only touched the surface of how SQL Server implements backup and recovery.
The main lesson to digest from this article is the importance of the transaction log. Too many times new SQL Server databases are implemented with very small transaction logs coupled with using the truncate log on checkpoint option. This is a dangerous combination for mission-critical production applications because it can cause transactions to be lost during a hardware, software, or application failure. And every transaction is precious in most production systems. Make sure your SQL Server databases are protected by planning for and implementing a transaction log backup and recovery plan.
The Basics of LoggingThe CREATE DATABASE statement is used to create a Microsoft SQL Server database. The LOG ON clause is used to identify the transaction log file for the database to be created. Once created, data is stored in the database file, and a record of the modifications to that data is recorded in the transaction log file.
As database modifications are made, the transaction log for the database will grow. Since most database changes are logged, you will need to actively monitor the size of the transaction log files because if the data is constantly changing, the log will be continuously growing.
At each checkpoint, Microsoft SQL Server will guarantee that all log records and all modified database pages are written safely to disk. Transaction log files are used by Microsoft SQL Server during database recovery operations to commit completed transactions and rollback uncompleted transactions. Information recorded on the transaction log includes:
the beginning time of each transaction
the actual changes made to the data and enough information to undo the modifications made during each transaction (accomplished using before and after images of the data)
the allocation and deallocation of database pages
the actual commit or rollback of each transaction
Using this data, Microsoft SQL Server can accomplish data integrity operations to ensure consistent data is maintained in the database. The transaction log is used when SQL Server is restarted, when transactions are rolled back, and to restore the database to the state prior to the transaction.
When SQL Server is restarted, each database goes through a recovery process. SQL Server checks to determine which transactions must be rolled forward. This occurs for transactions where it is unknown if all the modifications were actually written from the cache to disk. Because a checkpoint forces all modified pages to disk, it represents the point at which the startup recovery must start rolling transactions forward. Because all pages modified before the checkpoint are guaranteed to be on disk, there is no need to roll forward anything done before the checkpoint.
When a transaction is rolled back SQL Server copies before images to the database for every modification made since the BEGIN TRANSACTION.
During a recovery scenario you can use the transaction log to restore a database. This causes a roll forward of the transaction log. During a roll forward SQL Server will copy after images of each modification to the database. Using the logged data SQL Server ensures that each modification is applied in the same order that it originally occurred.
You can see where the transaction log is a useful item to have around in case of database errors, transaction errors, and to ensure data integrity.
Some Operations Are Not Always LoggedMicrosoft SQL Server avoids logging in certain situations to avoid “out of space” conditions caused by rapid growth in transaction log files.
For some large operations, such as CREATE INDEX, Microsoft SQL Server will not log every new page. Instead, SQL Server records enough information to determine that a CREATE INDEX happened, so that it can either be recreated for a roll forward, or removed during a roll back.
Additionally, if the select into/bulkcopy database option is set to TRUE, Microsoft SQL Server will not record the following operations in the transaction log: bulk load operations, SELECT INTO statements, and WRITETEXT and UPDATETEXT statements. Because these operations are not recorded in the transaction log, SQL Server can not use the restore operation on the transaction log to recover these operations. Since SQL Server has no knowledge of the operations occurring, it can not recover the data.
If one of these operations occurs when the select into/bulkcopy option is TRUE, be sure to backup the database so that the changes made be these operations are preserved if a subsequent restore is required.
Transaction Log BackupsTo ensure an efficient and effective backup and recovery strategy for your Microsoft SQL Server databases, you will need to implement a periodic transaction log backups. A transaction log backup is created using the BACKUP LOG command. A database can be restored to any point in time contained within the sequence of transaction logs you have backed up, up to the point of failure. If you do not backup your transaction logs before truncating them, you will only be able to restore your database to the last database backup you have created.
When Microsoft SQL Server finishes backing up the transaction log, it truncates the inactive portion of the transaction log. This frees up space on the transaction log. SQL Server can reuse this truncated space instead of causing the transaction log to continuously grow and consume more space. The active portion of the transaction log contains transactions that are still running and have not completed yet.
Microsoft SQL Server will try to take a checkpoint whenever the transaction log becomes 70 percent full, if a log full error occurs, and when SQL Server is shut down (unless using the NOWAIT option) it will take a checkpoint for each database.
The transaction log should not be backed up if the truncate log on checkpoint database option is set to TRUE. If you specify truncate log on checkpoint to be true, Microsoft SQL Server will clear out inactive transaction log entries at every checkpoint. This option essentially tells SQL Server that you will not be using the transaction log for restore operations. The transaction log is still required to roll back transactions and for SQL Server to determine how to recover databases when it is restarted. Use this option only for systems where it is okay for you to lose transactions during the course of a day, because you will only be able to restore your database back to the last backup that was taken. Applications of this nature are very rare in most production environments.
If a transaction log has been truncated (except by a BACKUP LOG) you should not backup that log until you take a database backup or differential database backup. A differential database backup will backup only data that has changed since the last full database backup.
You should also avoid backing up transaction logs any nonlogged operations have occurred in since the last database backup was created. Create a database or differential database backup instead.
And finally, if any files are added or deleted from the database, a transaction log backup should not be taken. Instead, you should create a full database backup.
Changing Database OptionsThe truncate log on checkpoint option can be changed at the database level. Use the system procedure named sp_dboption to change the configuration settings for a database. For example:
exec sp_dboption 'pubs', 'trunc. log on chkpt.', 'false'This will change the truncate log on checkpoint option to false for the pubs database. To see a list of all current database options set for a database, simply issue the system procedure without additional parameters, for example:
exec sp_dboption pubsYou can also use Enterprise Manager to set database options. When a database is first created, most of its options will be set to false. In the desktop edition of Microsoft SQL Server, however, the truncate log on checkpoint database option is set to true. This may not be a problem depending on the recovery requirements of the data stored in your desktop SQL Server databases.
You might also consider setting truncate log on checkpoint to TRUE during an application development cycle. Usually, it is not important to save every test transaction that is attempted while an application is in development.
ConclusionThis has been a brief introduction to using transaction logs with Microsoft SQL Server. The topic of database backup and recovery is complex and we have only touched the surface of how SQL Server implements backup and recovery.
The main lesson to digest from this article is the importance of the transaction log. Too many times new SQL Server databases are implemented with very small transaction logs coupled with using the truncate log on checkpoint option. This is a dangerous combination for mission-critical production applications because it can cause transactions to be lost during a hardware, software, or application failure. And every transaction is precious in most production systems. Make sure your SQL Server databases are protected by planning for and implementing a transaction log backup and recovery plan.
Backing Up and Restoring SQL Server Databases and Transaction Logs
General Concepts
The backing up and restoring of databases and transaction logs is a way that SQL Server provides to protect from data loss. The backup operation creates a copy of a database. This copy can be used to restore the database if media failure occurs or if the database is somehow damaged (for example, from user errors).
SQL Server 2000 supports the following kinds of backup:
Full database backup (it is a full copy of the database).
Transaction log backup (it contains a copy of the transaction log only).
Differential backup (it contains a copy of only the database pages modified since the last full database backup).
SQL Server 2000 supports three recovery models which determine how your data is backed up and what your exposure to data loss is. There are:
Simple recovery model
Full recovery model
Bulk-Logged recovery model
Simple Recovery modelThe Simple Recovery model allows the database to be recovered to the point of the last backup (to the most recent backup). With this recovery model, you cannot restore the database to the point of failure or to a specific point in time. Therefore, changes since the last backup will be lost.
The backup strategy for this recovery model consists of the full database backups only or full database backups and some differential backups. To recover a database, you should restore the most recent full database backup and then restore the most recent differential backup if it exists. The Simple Recovery model is similar to setting the trunc. log on chkpt database option in SQL Server 7.0 or earlier. This recovery model takes less time to perform the backup and restore in comparison with the Full and Bulk-Logged models and requires less disk space, but does not provide the opportunity to restore the database to the point of failure or to a specific point in time.
For example, if you make a full database backup of the pubs database on a Sunday at 1 AM, and make a differential backup of the pubs database on Monday at 1 AM and again on Tuesday at 1 AM, then suppose that the pubs database is damaged on Tuesday at 3 AM, you should restore the full database backup from Sunday 1 AM, and then restore the differential backup from Tuesday 1 AM. All changes since Tuesday 1 AM will be lost.
-- Create a full database backup of the pubs database on Sunday at 1AM
BACKUP DATABASE pubs TO pubs_back WITH INIT
GO
-- Time elapses.
-- Create a differential backup of the pubs database on Monday at 1AM
BACKUP DATABASE pubs TO pubs_back WITH DIFFERENTIAL
GO
-- Time elapses.
-- Create a differential backup of the pubs database on Tuesday at 1AM
BACKUP DATABASE pubs TO pubs_back WITH DIFFERENTIAL
GO
-- Time elapses.
-- The pubs database was damaged on Tuesday at 3 AM
-- Restore the full database from Sunday 1 AM without recovering
RESTORE DATABASE pubs FROM pubs_back WITH NORECOVERY
GO
-- Restore the differential backup from Tuesday 1 AM with recovering
RESTORE DATABASE pubs FROM pubs_back WITH FILE = 3, RECOVERY
GO
Full Recovery modelThe Full Recovery model allows the database to be recovered to the point of failure or to a specific point in time. This recovery model provides the best protection of your data, but requires more time to make the backup and restore. With the Full Recovery model, all operations, including bulk operations such as SELECT INTO, CREATE INDEX, and bulk loading data, are fully logged. The backup strategy for this recovery model consists of the full database backups (maybe with some differential backups) and transaction log backups. If the current transaction log file for the database is available and undamaged, you should perform the following steps to restore the database to the point of failure:
Back up the active transaction log. Restore the most recent full database backup without recovering the database.
Restore the most recent differential backups, if it exists.
Restore each transaction log backup created since the most recent full database backup (or the most recent differential backups, if differential backups exist) in the same sequence in which they were created without recovering the database.
Apply the transaction log backup created in Step 1, and recover the database.
For example, to perform the Full Recovery model for the pubs database at the following backup intervals:
Make the full database backup of the pubs database on Sunday at 1 AM.
Make the differential backups of the pubs database on Monday at 1 AM and on Tuesday at 1 AM.
Make the transaction log backups of the pubs database on Monday at 2 AM and on Tuesday at 2 AM.
So, if the primary data file of the pubs database was damaged on Tuesday at 3 AM, you should recover the pubs database by using the following steps:
Back up the active transaction log.
Restore the full database backup from Sunday 1 AM.
Restore the differential backup from Tuesday 1 AM.
Restore the transaction log from Tuesday 2 AM.
Apply the transaction log backup created in Step 1, and recover the database.
-- Create a full database backup of the pubs database on Sunday at 1AM
BACKUP DATABASE pubs TO pubs_back_db WITH INIT
GO
-- Time elapses.
-- Create a differential backup of the pubs database on Monday at 1AM
BACKUP DATABASE pubs TO pubs_back_db WITH DIFFERENTIAL
GO
-- Time elapses.
-- Create a transaction log backup of the pubs database
-- on Monday at 2AM
BACKUP LOG pubs TO pubs_back_log WITH INIT
GO
-- Time elapses.
-- Create a differential backup of the pubs database on Tuesday at 1AM
BACKUP DATABASE pubs TO pubs_back_db WITH DIFFERENTIAL
GO
-- Time elapses.
-- Create a transaction log backup of the pubs database
-- on Tuesday at 2AM
BACKUP LOG pubs TO pubs_back_log
GO
-- Time elapses.
-- The primary data file of the pubs database was damaged
-- on Tuesday at 3 AM
-- Back up the active transaction log.
BACKUP LOG pubs TO pubs_back_log
GO
-- Restore the full database from Sunday 1 AM without recovering
RESTORE DATABASE pubs FROM pubs_back_db WITH NORECOVERY
GO
-- Restore the differential backup from Tuesday 1AM without recovering
RESTORE DATABASE pubs FROM pubs_back_db WITH FILE = 3, NORECOVERY
GO
-- Restore the transaction log backup from Tuesday 2AM with recovering
RESTORE LOG pubs FROM pubs_back_log WITH FILE = 2, NORECOVERY
GO
-- Apply the last created log backup and recover the database
RESTORE LOG pubs FROM pubs_back_log WITH FILE = 3, RECOVERY
GO
Bulk-Logged Recovery modelThe Bulk-Logged Recovery model provides better performance in comparison with the Full Recovery model because the SELECT INTO, Bulk load operations, CREATE INDEX and WRITETEXT, UPDATETEXT operations are minimally logged. Full and Bulk-Logged Recovery models are similar, and you can switch between them easily. The Bulk-Logged Recovery model does not allow the database to be recovered to a specific point in time. Under this recovery model the transaction log backups capture both the log and the results of any bulk operations performed since the last backup, so it is not necessary to perform a full database backup after bulk copy operations complete.
Taken From Database Journal
The backing up and restoring of databases and transaction logs is a way that SQL Server provides to protect from data loss. The backup operation creates a copy of a database. This copy can be used to restore the database if media failure occurs or if the database is somehow damaged (for example, from user errors).
SQL Server 2000 supports the following kinds of backup:
Full database backup (it is a full copy of the database).
Transaction log backup (it contains a copy of the transaction log only).
Differential backup (it contains a copy of only the database pages modified since the last full database backup).
SQL Server 2000 supports three recovery models which determine how your data is backed up and what your exposure to data loss is. There are:
Simple recovery model
Full recovery model
Bulk-Logged recovery model
Simple Recovery modelThe Simple Recovery model allows the database to be recovered to the point of the last backup (to the most recent backup). With this recovery model, you cannot restore the database to the point of failure or to a specific point in time. Therefore, changes since the last backup will be lost.
The backup strategy for this recovery model consists of the full database backups only or full database backups and some differential backups. To recover a database, you should restore the most recent full database backup and then restore the most recent differential backup if it exists. The Simple Recovery model is similar to setting the trunc. log on chkpt database option in SQL Server 7.0 or earlier. This recovery model takes less time to perform the backup and restore in comparison with the Full and Bulk-Logged models and requires less disk space, but does not provide the opportunity to restore the database to the point of failure or to a specific point in time.
For example, if you make a full database backup of the pubs database on a Sunday at 1 AM, and make a differential backup of the pubs database on Monday at 1 AM and again on Tuesday at 1 AM, then suppose that the pubs database is damaged on Tuesday at 3 AM, you should restore the full database backup from Sunday 1 AM, and then restore the differential backup from Tuesday 1 AM. All changes since Tuesday 1 AM will be lost.
-- Create a full database backup of the pubs database on Sunday at 1AM
BACKUP DATABASE pubs TO pubs_back WITH INIT
GO
-- Time elapses.
-- Create a differential backup of the pubs database on Monday at 1AM
BACKUP DATABASE pubs TO pubs_back WITH DIFFERENTIAL
GO
-- Time elapses.
-- Create a differential backup of the pubs database on Tuesday at 1AM
BACKUP DATABASE pubs TO pubs_back WITH DIFFERENTIAL
GO
-- Time elapses.
-- The pubs database was damaged on Tuesday at 3 AM
-- Restore the full database from Sunday 1 AM without recovering
RESTORE DATABASE pubs FROM pubs_back WITH NORECOVERY
GO
-- Restore the differential backup from Tuesday 1 AM with recovering
RESTORE DATABASE pubs FROM pubs_back WITH FILE = 3, RECOVERY
GO
Full Recovery modelThe Full Recovery model allows the database to be recovered to the point of failure or to a specific point in time. This recovery model provides the best protection of your data, but requires more time to make the backup and restore. With the Full Recovery model, all operations, including bulk operations such as SELECT INTO, CREATE INDEX, and bulk loading data, are fully logged. The backup strategy for this recovery model consists of the full database backups (maybe with some differential backups) and transaction log backups. If the current transaction log file for the database is available and undamaged, you should perform the following steps to restore the database to the point of failure:
Back up the active transaction log. Restore the most recent full database backup without recovering the database.
Restore the most recent differential backups, if it exists.
Restore each transaction log backup created since the most recent full database backup (or the most recent differential backups, if differential backups exist) in the same sequence in which they were created without recovering the database.
Apply the transaction log backup created in Step 1, and recover the database.
For example, to perform the Full Recovery model for the pubs database at the following backup intervals:
Make the full database backup of the pubs database on Sunday at 1 AM.
Make the differential backups of the pubs database on Monday at 1 AM and on Tuesday at 1 AM.
Make the transaction log backups of the pubs database on Monday at 2 AM and on Tuesday at 2 AM.
So, if the primary data file of the pubs database was damaged on Tuesday at 3 AM, you should recover the pubs database by using the following steps:
Back up the active transaction log.
Restore the full database backup from Sunday 1 AM.
Restore the differential backup from Tuesday 1 AM.
Restore the transaction log from Tuesday 2 AM.
Apply the transaction log backup created in Step 1, and recover the database.
-- Create a full database backup of the pubs database on Sunday at 1AM
BACKUP DATABASE pubs TO pubs_back_db WITH INIT
GO
-- Time elapses.
-- Create a differential backup of the pubs database on Monday at 1AM
BACKUP DATABASE pubs TO pubs_back_db WITH DIFFERENTIAL
GO
-- Time elapses.
-- Create a transaction log backup of the pubs database
-- on Monday at 2AM
BACKUP LOG pubs TO pubs_back_log WITH INIT
GO
-- Time elapses.
-- Create a differential backup of the pubs database on Tuesday at 1AM
BACKUP DATABASE pubs TO pubs_back_db WITH DIFFERENTIAL
GO
-- Time elapses.
-- Create a transaction log backup of the pubs database
-- on Tuesday at 2AM
BACKUP LOG pubs TO pubs_back_log
GO
-- Time elapses.
-- The primary data file of the pubs database was damaged
-- on Tuesday at 3 AM
-- Back up the active transaction log.
BACKUP LOG pubs TO pubs_back_log
GO
-- Restore the full database from Sunday 1 AM without recovering
RESTORE DATABASE pubs FROM pubs_back_db WITH NORECOVERY
GO
-- Restore the differential backup from Tuesday 1AM without recovering
RESTORE DATABASE pubs FROM pubs_back_db WITH FILE = 3, NORECOVERY
GO
-- Restore the transaction log backup from Tuesday 2AM with recovering
RESTORE LOG pubs FROM pubs_back_log WITH FILE = 2, NORECOVERY
GO
-- Apply the last created log backup and recover the database
RESTORE LOG pubs FROM pubs_back_log WITH FILE = 3, RECOVERY
GO
Bulk-Logged Recovery modelThe Bulk-Logged Recovery model provides better performance in comparison with the Full Recovery model because the SELECT INTO, Bulk load operations, CREATE INDEX and WRITETEXT, UPDATETEXT operations are minimally logged. Full and Bulk-Logged Recovery models are similar, and you can switch between them easily. The Bulk-Logged Recovery model does not allow the database to be recovered to a specific point in time. Under this recovery model the transaction log backups capture both the log and the results of any bulk operations performed since the last backup, so it is not necessary to perform a full database backup after bulk copy operations complete.
Taken From Database Journal
Wednesday, April 26, 2006
Stored Procedures Part 1
Using Stored Procedures in SQL
Most of us, the database programmers, have used Stored Procedures. May be not all of us knows about why we use them. This article is for those who have used/never used stored procedures, and are yet to understand why everyone suggests using them in your Database.
Stored Procedures – What are they?
Stored procedure is a set of pre-defined Transact-SQL statements, used to perform a specific task. There can be multiple statements in a stored procedure, and all the multiple statements are clubbed in to one database object.
How to create a stored procedure?
Creating a stored procedure is as easy as running the “Create Procedure” statement followed by the SQL script. You can run your Create Procedure statement from the SQL Query Analyzer, or can use the New Procedure menu item in the Enterprise Manager.
The simplest skeleton of a stored procedure.
CREATE PROC procedure_name
[ { @parameter data_type }
]
AS sql_statement
Check the basic building blocks of a stored procedure.
A stored procedure includes
1. A CREATE PROC (CREATE PROCEDURE) statement;
2. The procedure name;
3. The parameter list
4. And the SQL statements.
Even though there are numerous other options available while we define a stored procedure, I kept it simple, just to give you a basic idea about creating stored procedures.
Advantages!
Almost every database Guru that you will meet, will suggest using stored procedures. For you, it will seem as if most of them blindly believes in stored procedures. But there are reasons for this. This is what I am trying to explore in this article.
1. Performance
All the SQL statements, that you send to your database server passes through a series of actions, called execution. These are the steps that your SQL statement passes through before the data is returned to the client.
User sends request to execute the Stored Procedure. SQL Server checks for syntax errors. Identifies and checks the aliases in the FROM clause. Creates a query plan. Compiles the query and. Executes the query plan and return the requested data.
See, lots of things are happening inside that we didn’t knew about. Now, the crucial question. Does a stored procedure bypass all these?
In a way, yes. The previous versions of SQL Server stored the compiled execution plan in system tables, making them partially pre-compiled. This improved performance, because the Server did not have to compile the stored procedure each and every time it is called.
In later versions of SQL Server, there were a large number of changes in statement processing. Now, the stored procedure is stored in a procedure cache when it is called, making subsequent calls faster.
2. Security
Stored procedures provide significant benefits when it comes to security. By using a stored procedure, you can grant permissions to certain users to access data, reducing the immense coding that you need to do in your client applications. This is one of the best ways to control access to your data.
3. Modifications/Maintenance
If you use stored procedures for database access, any change in the database can be reflected on to the client application without much effort. This is because you know exactly where the data is accessed from, and you also know exactly where you need to alter. This means no scuba diving in to thousands of lines of source code to identify areas where you need to alter and no headache of re-deploying the client application.
4. Minimal processing at the client.
When creating a client/server application, normally it was the client who took care of the integrity of data that went in to the database. Managing Primary Keys, Foreign keys, cascaded deletion everything was done by the client, and the database server just had to store data given by the client.
Well friends, things have changed. Stored procedures help you write batch of SQL statements, which helps you manage the transactions, constraints etc. A little data aware code has to be written in to the client application, making it a thin-client application. These applications will be concerned more about displaying data in the way the user needs them and they know little about the database.
Take another scenario. You have a database with millions of rows and hundreds of tables. You need to do some calculations before updating each and every record. If you are fetching the complete data to the client, and is asking the client machine to process the data completely, then think about the overhead it creates. But when the client can execute a store procedure, where you have done the calculations prior to updating the records, you have a client, that doesn’t need to know about the calculations. This also reduces the amount of computing happening in the client, and the server takes care of tedious calculations.
5. Network traffic
Client applications always have to request/send data from the database server. These data are sent as packets, and travel through the network to the server.
To explain how stored procedures can help reduce network traffic, let us see another scenario, where a request for data is send from the client. The request is sent as an SQL statement, and here it is.
SELECT dbo.Tbl_Tablename.fieldID,
dbo.Tbl_Tablename.fieldName,
dbo.Tbl_Tablename.Title,
dbo.TBl_otherTableName.fieldID,
dbo.Tbl_Tablename.Published,
dbo.Tbl_Tablename.Updated,
dbo.Tbl_Tablename.SomeText,
dbo.Tbl_Tablename.TransactionDate,
dbo.Tbl_Tablename.Approved,
dbo.Tbl_Tablename.ApprovedBy,
dbo.Tbl_Tablename.ApprovalID
FROM
dbo.Tbl_Tablename
LEFT OUTER JOIN
dbo.TBl_otherTableName on dbo.Tbl_Tablename.fieldID=dbo.TBl_otherTableName.ID
Where
DateDiff ( wk, dbo.Tbl_Tablename.TransactionDate, getdate()) <= 1
and dbo.Tbl_Tablename.Approved = 0
518 Characters travel through the network, and when there are 20 client applications using this stored procedure 20 times a day, the number of characters passing through the network for just this request will be 2,07,200!
You see the difference now. If it was a stored procedure, lets call it SP_fetchSomething, there are only 6800 characters in the network for the request. A saving of 2,004,00!
As you have seen the five major points that I use to explain why I used a stored procedure, I hope you will also elect to intelligently use this awesome technology in your next database design.
Most of us, the database programmers, have used Stored Procedures. May be not all of us knows about why we use them. This article is for those who have used/never used stored procedures, and are yet to understand why everyone suggests using them in your Database.
Stored Procedures – What are they?
Stored procedure is a set of pre-defined Transact-SQL statements, used to perform a specific task. There can be multiple statements in a stored procedure, and all the multiple statements are clubbed in to one database object.
How to create a stored procedure?
Creating a stored procedure is as easy as running the “Create Procedure” statement followed by the SQL script. You can run your Create Procedure statement from the SQL Query Analyzer, or can use the New Procedure menu item in the Enterprise Manager.
The simplest skeleton of a stored procedure.
CREATE PROC procedure_name
[ { @parameter data_type }
]
AS sql_statement
Check the basic building blocks of a stored procedure.
A stored procedure includes
1. A CREATE PROC (CREATE PROCEDURE) statement;
2. The procedure name;
3. The parameter list
4. And the SQL statements.
Even though there are numerous other options available while we define a stored procedure, I kept it simple, just to give you a basic idea about creating stored procedures.
Advantages!
Almost every database Guru that you will meet, will suggest using stored procedures. For you, it will seem as if most of them blindly believes in stored procedures. But there are reasons for this. This is what I am trying to explore in this article.
1. Performance
All the SQL statements, that you send to your database server passes through a series of actions, called execution. These are the steps that your SQL statement passes through before the data is returned to the client.
User sends request to execute the Stored Procedure. SQL Server checks for syntax errors. Identifies and checks the aliases in the FROM clause. Creates a query plan. Compiles the query and. Executes the query plan and return the requested data.
See, lots of things are happening inside that we didn’t knew about. Now, the crucial question. Does a stored procedure bypass all these?
In a way, yes. The previous versions of SQL Server stored the compiled execution plan in system tables, making them partially pre-compiled. This improved performance, because the Server did not have to compile the stored procedure each and every time it is called.
In later versions of SQL Server, there were a large number of changes in statement processing. Now, the stored procedure is stored in a procedure cache when it is called, making subsequent calls faster.
2. Security
Stored procedures provide significant benefits when it comes to security. By using a stored procedure, you can grant permissions to certain users to access data, reducing the immense coding that you need to do in your client applications. This is one of the best ways to control access to your data.
3. Modifications/Maintenance
If you use stored procedures for database access, any change in the database can be reflected on to the client application without much effort. This is because you know exactly where the data is accessed from, and you also know exactly where you need to alter. This means no scuba diving in to thousands of lines of source code to identify areas where you need to alter and no headache of re-deploying the client application.
4. Minimal processing at the client.
When creating a client/server application, normally it was the client who took care of the integrity of data that went in to the database. Managing Primary Keys, Foreign keys, cascaded deletion everything was done by the client, and the database server just had to store data given by the client.
Well friends, things have changed. Stored procedures help you write batch of SQL statements, which helps you manage the transactions, constraints etc. A little data aware code has to be written in to the client application, making it a thin-client application. These applications will be concerned more about displaying data in the way the user needs them and they know little about the database.
Take another scenario. You have a database with millions of rows and hundreds of tables. You need to do some calculations before updating each and every record. If you are fetching the complete data to the client, and is asking the client machine to process the data completely, then think about the overhead it creates. But when the client can execute a store procedure, where you have done the calculations prior to updating the records, you have a client, that doesn’t need to know about the calculations. This also reduces the amount of computing happening in the client, and the server takes care of tedious calculations.
5. Network traffic
Client applications always have to request/send data from the database server. These data are sent as packets, and travel through the network to the server.
To explain how stored procedures can help reduce network traffic, let us see another scenario, where a request for data is send from the client. The request is sent as an SQL statement, and here it is.
SELECT dbo.Tbl_Tablename.fieldID,
dbo.Tbl_Tablename.fieldName,
dbo.Tbl_Tablename.Title,
dbo.TBl_otherTableName.fieldID,
dbo.Tbl_Tablename.Published,
dbo.Tbl_Tablename.Updated,
dbo.Tbl_Tablename.SomeText,
dbo.Tbl_Tablename.TransactionDate,
dbo.Tbl_Tablename.Approved,
dbo.Tbl_Tablename.ApprovedBy,
dbo.Tbl_Tablename.ApprovalID
FROM
dbo.Tbl_Tablename
LEFT OUTER JOIN
dbo.TBl_otherTableName on dbo.Tbl_Tablename.fieldID=dbo.TBl_otherTableName.ID
Where
DateDiff ( wk, dbo.Tbl_Tablename.TransactionDate, getdate()) <= 1
and dbo.Tbl_Tablename.Approved = 0
518 Characters travel through the network, and when there are 20 client applications using this stored procedure 20 times a day, the number of characters passing through the network for just this request will be 2,07,200!
You see the difference now. If it was a stored procedure, lets call it SP_fetchSomething, there are only 6800 characters in the network for the request. A saving of 2,004,00!
As you have seen the five major points that I use to explain why I used a stored procedure, I hope you will also elect to intelligently use this awesome technology in your next database design.
Tuesday, April 25, 2006
Intro to User Defined Functions(Nice One)
Introduction
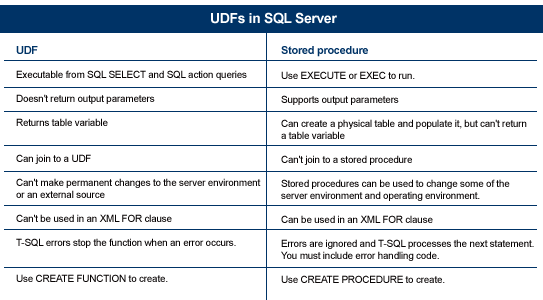
The ability to create a user-defined function (UDF) is a new feature added to SQL Server 2000. Developers have been asking Microsoft to add this feature for several versions of the product, so let's take a quick look at how to create a few simple UDFs to see if they can help you in your programming endeavors.
Creating a Simple UDF
A user-defined function is a database object that encapsulates one or more Transact-SQL statements for reuse. This definition is similar to the one for stored procedures, but there are many important differences between user-defined functions and stored procedures?the most pronounced being what types of data they can return. Let?s create one so you can see how easy they are to create and reference.
The following statement shows how to create a function that accepts two input parameters, sums them together and then returns the sum to the calling statement.
CREATE FUNCTION fx_SumTwoValues
( @Val1 int, @Val2 int )
RETURNS int
AS
BEGIN
RETURN (@Val1+@Val2)
END
The structure of the CREATE FUNCTION statement is fairly straightforward. You provide an object name (fx_SumTwoValues), input parameters (@Val1 and @Val2), the type of data the function will return () and the statement(s) the function executes are located between the BEGIN?END block. The following SELECT statement calls the function. Note that the two-part name (owner.object_name) is required when calling this function.
SELECT dbo.fx_SumTwoValues(1,2) AS SumOfTwoValues
SumOfTwoValues
--------------
3
When the SELECT is executed, the input parameters 1 and 2 are added together and the sum 3 is returned. You can use any values that either are, or can be, implicitly converted to an int data type for the input parameters. Keep in mind, though, that only an int can be returned, so the following statement will not produce the desired results.
SELECT dbo.fx_SumTwoValues(1.98,2.78) AS SumOfTwoValues
SumOfTwoValues
--------------
3
The function returns a 3, which indicates the decimal portion of the parameters are truncated before the calculation occurs.
SQL Server?s ability to implicitly convert data allows the following to execute successfully.
SELECT dbo.fx_SumTwoValues('7','7') AS SumOfTwoValues
SumOfTwoValues
--------------
14
When values that cannot be converted to an int are passed to the function, the following error message is generated.
SELECT dbo.fx_SumTwoValues('Y','7') AS SumOfTwoValues
Server:Msg 245,Level 16,State 1,Line 1
Syntax error converting the varchar value 'Y'to a column of data type int.
Three Types of User-Defined Functions
Now that you have seen how easy it is to create and implement a simple function, let?s cover the three different types of user-defined functions and some of the nuances of how they are implemented.
Scalar Functions
A scalar function returns a single value of the data type referenced in the RETURNS clause of the CREATE FUNCTION statement. The returned data can be of any type except text, ntext, image, cursor, or timestamp.
The example we covered in the previous section is a scalar function. Although the previous example only contained one statement in the BEGIN?END block, a scalar function can contain an unlimited number of statements as long as only one value is returned. The following example uses a WHILE construct to demonstrate this.
CREATE FUNCTION fx_SumTwoValues2
( @Val1 int, @Val2 int )
RETURNS int
AS
BEGIN
WHILE @Val1 <100
BEGIN
SET @Val1 =@Val1 +1
END
RETURN (@Val1+@Val2)
END
go
SELECT dbo.fx_SumTwoValues2(1,7) AS SumOfTwoValues
SumOfTwoValues
--------------
107
The @Val1 input parameter is set to 1 when the function is called, but the WHILE increments the parameter to 100 before the RETURN statement is executed. Note that the two-part name (owner.object_name) is used to call the function. Scalar functions require that their two-part names be used when they are called. As you will see in the next two sections, this is not the case with the other two types of functions.
Inline Table-Valued Functions
An inline table-valued function returns a variable of data type table whose value is derived from a single SELECT statement. Since the return value is derived from the SELECT statement, there is no BEGIN/END block needed in the CREATE FUNCTION statement. There is also no need to specify the table variable name (or column definitions for the table variable) because the structure of the returned value is generated from the columns that compose the SELECT statement. Because the results are a function of the columns referenced in the SELECT, no duplicate column names are allowed and all derived columns must have an associated alias.
The following uses the Customer table in the Northwind database to show how an inline table-valued function is implemented.
USE Northwind
go
CREATE FUNCTION fx_Customers_ByCity
( @City nvarchar(15) )
RETURNS table
AS
RETURN (
SELECT CompanyName
FROM Customers
WHERE City =@City
)
go
SELECT * FROM fx_Customers_ByCity('London')
CompanyName
----------------------------------------
Around the Horn
. . .
Seven Seas Imports
Multi-Statement Table-Valued Functions
The multi-statement table-valued function is slightly more complicated than the other two types of functions because it uses multiple statements to build the table that is returned to the calling statement. Unlike the inline table-valued function, a table variable must be explicitly declared and defined. The following example shows how to implement a multi-statement table-valued function that populates and returns a table variable.
USE Northwind
go
CREATE FUNCTION fx_OrdersByDateRangeAndCount
( @OrderDateStart smalldatetime,
@OrderDateEnd smalldatetime,
@OrderCount smallint )
RETURNS @OrdersByDateRange TABLE
( CustomerID nchar(5),
CompanyName nvarchar(40),
OrderCount smallint,
Ranking char(1) )
AS
BEGIN
--Statement 1
INSERT @OrdersByDateRange
SELECT a.CustomerID,
a.CompanyName,
COUNT(a.CustomerID)AS OrderCount,
'B'
FROM Customers a
JOIN Orders b ON a.CustomerID =b.CustomerID
WHERE OrderDate BETWEEN @OrderDateStart AND @OrderDateEnd
GROUP BY a.CustomerID,a.CompanyName
HAVING COUNT(a.CustomerID)>@OrderCount
--Statement 2
UPDATE @OrdersByDateRange
SET Ranking ='A'
WHERE CustomerID IN (SELECT TOP 5 WITH TIES CustomerID
FROM (SELECT a.CustomerID,
COUNT(a.CustomerID)AS OrderTotal
FROM Customers a
JOIN Orders b ON a.CustomerID =b.CustomerID
GROUP BY a.CustomerID) AS DerivedTable
ORDER BY OrderTotal DESC)
RETURN
END
The main difference between this example and the one in the previous section is that we were required to specify the structure of the @OrdersByDateRange table variable used to hold the resultset and list @OrdersByDateRange in the RETURNS clause. As you can see from the input parameter list, the function accepts a start date, an end date and an order count value to filter the resultset.
The first statement (--Statement 1) uses the input parameters to populate the table variable with customers who meet the specified criteria. The second statement (-Statement 2) updates the rows in table variable to identify the top five overall order placers. The IN portion of the UPDATE may seem a little confusing at first glance, but all its doing is using a derived table to select the CustomerID values of the top five order producers. Derived tables are discussed in Chapter 4. You can use the following to find the companies who have submitted more than two orders between 1/1/96 and 1/1/97.
SELECT *
FROM fx_OrdersByDateRangeAndCount ('1/1/96','1/1/97',2)
ORDER By Ranking
CustomerID CompanyName OrderCount Ranking
---------- ------------------------------ ---------- -------
ERNSH Ernst Handel 6 A
FOLKO Folk och f䠈B 3 A
HUNGO Hungry Owl All-Night Grocers 5 A
QUICK QUICK-Stop 6 A
SAVEA Save-a-lot Markets 3 A
SEVES Seven Seas Imports 3 B
SPLIR Split Rail Beer &Ale 5 B
...
The rows ranking values of ?A? indicate the top five order placers of all companies. The function allows you to perform two operations with one object. Retrieve the companies who have placed more than two orders between 1/1/96 and 1/1/97 and let me know if any of these companies are my top five order producers.
One of the advantages of using this type of function over a view is that the body of the function can contain multiple SQL statements to populate the table variable, whereas a view is composed of only one statement. The advantage of using multi-statement table-valued function versus a stored procedure is that the function can be referenced in the FROM clause of a SELECT statement while a stored procedure cannot. Had a stored procedure been used to return the same data, the resultset could only be accessed with the EXECUTE command.
A Real-World Example
Now that you have an idea of the different types of functions available in SQL Server 2000, let's wrap up this article with an example you might be able to use on one of your projects. The following statements create a function that determines the last day of the month (LDOM) for a given date parameter.
CREATE FUNCTION fx_LDOM
( @Date varchar(20) )
RETURNS datetime
AS
BEGIN
--ensure valid date
IF ISDATE(@Date) = 1
BEGIN
--determine first day of month
SET @Date = DATEADD(day,-DAY(@Date)+1,@Date)
--determine last day of month
SET @Date = DATEADD(day,-1,DATEADD(month,1,@Date))
END
ELSE
SET @Date = '1/1/80'
RETURN @Date
END
The function's parameter (@Date) is defined as varchar(20), so error-checking code can be implemented. The ISDATE function makes sure the supplied value is a valid date. When an invalid date value is supplied, the function returns '1/1/80' to the calling statement. If you do not use this type of error-checking, the call to the function will fail when an invalid date is supplied.
When a valid date value is supplied, the DATEADD function is used to:
Determine the first day of the month, and
Determine the last day of the month.
If you have never used DATEADD before this may seem a little confusing, but a quick explanation should eliminate any that might exist. You use DATEADD to add or substract a date/time unit from a given date. The first parameter (in this case 'day') indicates the portion of the date that should be incremented. You can also specify year, quarter, month...millisecond. The second parameter is the number of units to add or substract. When subtracting, you simply make the value negative as shown in the example. The third parameter is the date value on which the calculation is performed.
The first day of the month is determined by calculating the number of elapsed days in the supplied parameter with the DAY function, adding 1 and then substracting it from the parameter. For an @Date value of 1/15/01, it simply subtracts 14 (15-1) days to get 1/1/01.
The last day of the month is determined by adding 1 month to the current month value and subtracting one day. So, 1/1/01 plus 1 month is equal to 2/1/01 and when you substract one day you get: 1/31/01.
The following shows how fx_LDOM is used in a SELECT statement to calculate the number of days remaining in a month.
CREATE TABLE fx_Testing (DateValue datetime)
go
INSERT fx_Testing VALUES ('1/1/01')
INSERT fx_Testing VALUES ('2/15/01')
INSERT fx_Testing VALUES ('2/15/02')
INSERT fx_Testing VALUES ('2/15/03')
INSERT fx_Testing VALUES ('2/15/04')
SELECT DateValue,
dbo.fx_LDOM(DateValue) AS LDOM,
DATEDIFF(day,DateValue,dbo.fx_LDOM(DateValue)) AS DaysLeftInMonth
FROM fx_Testing
DateValue LDOM DaysLeftInMonth
------------------------ ----------------------- ---------------
2001-01-01 00:00:00.000 2001-01-31 00:00:00.000 30
2001-02-15 00:00:00.000 2001-02-28 00:00:00.000 13
2002-02-15 00:00:00.000 2002-02-28 00:00:00.000 13
2003-02-15 00:00:00.000 2003-02-28 00:00:00.000 13
2004-02-15 00:00:00.000 2004-02-29 00:00:00.000 14
The DATEDIFF function is used to determine the difference between two dates. In this case, the number of days between the value in the DateValue column and the last day of the month calculated by fx_LDOM.
Taken from SQLTeam
The ability to create a user-defined function (UDF) is a new feature added to SQL Server 2000. Developers have been asking Microsoft to add this feature for several versions of the product, so let's take a quick look at how to create a few simple UDFs to see if they can help you in your programming endeavors.
Creating a Simple UDF
A user-defined function is a database object that encapsulates one or more Transact-SQL statements for reuse. This definition is similar to the one for stored procedures, but there are many important differences between user-defined functions and stored procedures?the most pronounced being what types of data they can return. Let?s create one so you can see how easy they are to create and reference.
The following statement shows how to create a function that accepts two input parameters, sums them together and then returns the sum to the calling statement.
CREATE FUNCTION fx_SumTwoValues
( @Val1 int, @Val2 int )
RETURNS int
AS
BEGIN
RETURN (@Val1+@Val2)
END
The structure of the CREATE FUNCTION statement is fairly straightforward. You provide an object name (fx_SumTwoValues), input parameters (@Val1 and @Val2), the type of data the function will return () and the statement(s) the function executes are located between the BEGIN?END block. The following SELECT statement calls the function. Note that the two-part name (owner.object_name) is required when calling this function.
SELECT dbo.fx_SumTwoValues(1,2) AS SumOfTwoValues
SumOfTwoValues
--------------
3
When the SELECT is executed, the input parameters 1 and 2 are added together and the sum 3 is returned. You can use any values that either are, or can be, implicitly converted to an int data type for the input parameters. Keep in mind, though, that only an int can be returned, so the following statement will not produce the desired results.
SELECT dbo.fx_SumTwoValues(1.98,2.78) AS SumOfTwoValues
SumOfTwoValues
--------------
3
The function returns a 3, which indicates the decimal portion of the parameters are truncated before the calculation occurs.
SQL Server?s ability to implicitly convert data allows the following to execute successfully.
SELECT dbo.fx_SumTwoValues('7','7') AS SumOfTwoValues
SumOfTwoValues
--------------
14
When values that cannot be converted to an int are passed to the function, the following error message is generated.
SELECT dbo.fx_SumTwoValues('Y','7') AS SumOfTwoValues
Server:Msg 245,Level 16,State 1,Line 1
Syntax error converting the varchar value 'Y'to a column of data type int.
Three Types of User-Defined Functions
Now that you have seen how easy it is to create and implement a simple function, let?s cover the three different types of user-defined functions and some of the nuances of how they are implemented.
Scalar Functions
A scalar function returns a single value of the data type referenced in the RETURNS clause of the CREATE FUNCTION statement. The returned data can be of any type except text, ntext, image, cursor, or timestamp.
The example we covered in the previous section is a scalar function. Although the previous example only contained one statement in the BEGIN?END block, a scalar function can contain an unlimited number of statements as long as only one value is returned. The following example uses a WHILE construct to demonstrate this.
CREATE FUNCTION fx_SumTwoValues2
( @Val1 int, @Val2 int )
RETURNS int
AS
BEGIN
WHILE @Val1 <100
BEGIN
SET @Val1 =@Val1 +1
END
RETURN (@Val1+@Val2)
END
go
SELECT dbo.fx_SumTwoValues2(1,7) AS SumOfTwoValues
SumOfTwoValues
--------------
107
The @Val1 input parameter is set to 1 when the function is called, but the WHILE increments the parameter to 100 before the RETURN statement is executed. Note that the two-part name (owner.object_name) is used to call the function. Scalar functions require that their two-part names be used when they are called. As you will see in the next two sections, this is not the case with the other two types of functions.
Inline Table-Valued Functions
An inline table-valued function returns a variable of data type table whose value is derived from a single SELECT statement. Since the return value is derived from the SELECT statement, there is no BEGIN/END block needed in the CREATE FUNCTION statement. There is also no need to specify the table variable name (or column definitions for the table variable) because the structure of the returned value is generated from the columns that compose the SELECT statement. Because the results are a function of the columns referenced in the SELECT, no duplicate column names are allowed and all derived columns must have an associated alias.
The following uses the Customer table in the Northwind database to show how an inline table-valued function is implemented.
USE Northwind
go
CREATE FUNCTION fx_Customers_ByCity
( @City nvarchar(15) )
RETURNS table
AS
RETURN (
SELECT CompanyName
FROM Customers
WHERE City =@City
)
go
SELECT * FROM fx_Customers_ByCity('London')
CompanyName
----------------------------------------
Around the Horn
. . .
Seven Seas Imports
Multi-Statement Table-Valued Functions
The multi-statement table-valued function is slightly more complicated than the other two types of functions because it uses multiple statements to build the table that is returned to the calling statement. Unlike the inline table-valued function, a table variable must be explicitly declared and defined. The following example shows how to implement a multi-statement table-valued function that populates and returns a table variable.
USE Northwind
go
CREATE FUNCTION fx_OrdersByDateRangeAndCount
( @OrderDateStart smalldatetime,
@OrderDateEnd smalldatetime,
@OrderCount smallint )
RETURNS @OrdersByDateRange TABLE
( CustomerID nchar(5),
CompanyName nvarchar(40),
OrderCount smallint,
Ranking char(1) )
AS
BEGIN
--Statement 1
INSERT @OrdersByDateRange
SELECT a.CustomerID,
a.CompanyName,
COUNT(a.CustomerID)AS OrderCount,
'B'
FROM Customers a
JOIN Orders b ON a.CustomerID =b.CustomerID
WHERE OrderDate BETWEEN @OrderDateStart AND @OrderDateEnd
GROUP BY a.CustomerID,a.CompanyName
HAVING COUNT(a.CustomerID)>@OrderCount
--Statement 2
UPDATE @OrdersByDateRange
SET Ranking ='A'
WHERE CustomerID IN (SELECT TOP 5 WITH TIES CustomerID
FROM (SELECT a.CustomerID,
COUNT(a.CustomerID)AS OrderTotal
FROM Customers a
JOIN Orders b ON a.CustomerID =b.CustomerID
GROUP BY a.CustomerID) AS DerivedTable
ORDER BY OrderTotal DESC)
RETURN
END
The main difference between this example and the one in the previous section is that we were required to specify the structure of the @OrdersByDateRange table variable used to hold the resultset and list @OrdersByDateRange in the RETURNS clause. As you can see from the input parameter list, the function accepts a start date, an end date and an order count value to filter the resultset.
The first statement (--Statement 1) uses the input parameters to populate the table variable with customers who meet the specified criteria. The second statement (-Statement 2) updates the rows in table variable to identify the top five overall order placers. The IN portion of the UPDATE may seem a little confusing at first glance, but all its doing is using a derived table to select the CustomerID values of the top five order producers. Derived tables are discussed in Chapter 4. You can use the following to find the companies who have submitted more than two orders between 1/1/96 and 1/1/97.
SELECT *
FROM fx_OrdersByDateRangeAndCount ('1/1/96','1/1/97',2)
ORDER By Ranking
CustomerID CompanyName OrderCount Ranking
---------- ------------------------------ ---------- -------
ERNSH Ernst Handel 6 A
FOLKO Folk och f䠈B 3 A
HUNGO Hungry Owl All-Night Grocers 5 A
QUICK QUICK-Stop 6 A
SAVEA Save-a-lot Markets 3 A
SEVES Seven Seas Imports 3 B
SPLIR Split Rail Beer &Ale 5 B
...
The rows ranking values of ?A? indicate the top five order placers of all companies. The function allows you to perform two operations with one object. Retrieve the companies who have placed more than two orders between 1/1/96 and 1/1/97 and let me know if any of these companies are my top five order producers.
One of the advantages of using this type of function over a view is that the body of the function can contain multiple SQL statements to populate the table variable, whereas a view is composed of only one statement. The advantage of using multi-statement table-valued function versus a stored procedure is that the function can be referenced in the FROM clause of a SELECT statement while a stored procedure cannot. Had a stored procedure been used to return the same data, the resultset could only be accessed with the EXECUTE command.
A Real-World Example
Now that you have an idea of the different types of functions available in SQL Server 2000, let's wrap up this article with an example you might be able to use on one of your projects. The following statements create a function that determines the last day of the month (LDOM) for a given date parameter.
CREATE FUNCTION fx_LDOM
( @Date varchar(20) )
RETURNS datetime
AS
BEGIN
--ensure valid date
IF ISDATE(@Date) = 1
BEGIN
--determine first day of month
SET @Date = DATEADD(day,-DAY(@Date)+1,@Date)
--determine last day of month
SET @Date = DATEADD(day,-1,DATEADD(month,1,@Date))
END
ELSE
SET @Date = '1/1/80'
RETURN @Date
END
The function's parameter (@Date) is defined as varchar(20), so error-checking code can be implemented. The ISDATE function makes sure the supplied value is a valid date. When an invalid date value is supplied, the function returns '1/1/80' to the calling statement. If you do not use this type of error-checking, the call to the function will fail when an invalid date is supplied.
When a valid date value is supplied, the DATEADD function is used to:
Determine the first day of the month, and
Determine the last day of the month.
If you have never used DATEADD before this may seem a little confusing, but a quick explanation should eliminate any that might exist. You use DATEADD to add or substract a date/time unit from a given date. The first parameter (in this case 'day') indicates the portion of the date that should be incremented. You can also specify year, quarter, month...millisecond. The second parameter is the number of units to add or substract. When subtracting, you simply make the value negative as shown in the example. The third parameter is the date value on which the calculation is performed.
The first day of the month is determined by calculating the number of elapsed days in the supplied parameter with the DAY function, adding 1 and then substracting it from the parameter. For an @Date value of 1/15/01, it simply subtracts 14 (15-1) days to get 1/1/01.
The last day of the month is determined by adding 1 month to the current month value and subtracting one day. So, 1/1/01 plus 1 month is equal to 2/1/01 and when you substract one day you get: 1/31/01.
The following shows how fx_LDOM is used in a SELECT statement to calculate the number of days remaining in a month.
CREATE TABLE fx_Testing (DateValue datetime)
go
INSERT fx_Testing VALUES ('1/1/01')
INSERT fx_Testing VALUES ('2/15/01')
INSERT fx_Testing VALUES ('2/15/02')
INSERT fx_Testing VALUES ('2/15/03')
INSERT fx_Testing VALUES ('2/15/04')
SELECT DateValue,
dbo.fx_LDOM(DateValue) AS LDOM,
DATEDIFF(day,DateValue,dbo.fx_LDOM(DateValue)) AS DaysLeftInMonth
FROM fx_Testing
DateValue LDOM DaysLeftInMonth
------------------------ ----------------------- ---------------
2001-01-01 00:00:00.000 2001-01-31 00:00:00.000 30
2001-02-15 00:00:00.000 2001-02-28 00:00:00.000 13
2002-02-15 00:00:00.000 2002-02-28 00:00:00.000 13
2003-02-15 00:00:00.000 2003-02-28 00:00:00.000 13
2004-02-15 00:00:00.000 2004-02-29 00:00:00.000 14
The DATEDIFF function is used to determine the difference between two dates. In this case, the number of days between the value in the DateValue column and the last day of the month calculated by fx_LDOM.
Taken from SQLTeam
Wednesday, April 19, 2006
How to replace substring in given string!!
Do it like this:-
THIS is to show how a string can be replaced by new text in the column.
UPDATE TABLE_NAME
SET COLUMN_NAME = REPLACE(COLUMN_NAME,'OLDTEXT','NEWTEXT')
THIS is to show how a string can be replaced by new text in the column.
UPDATE TABLE_NAME
SET COLUMN_NAME = REPLACE(COLUMN_NAME,'OLDTEXT','NEWTEXT')
Find Nth highest Salary
Its done like:-
SELECT MIN(SALARY) FROM EMPLOYEE
WHERE SALARY IN (SELECT DISTINCT TOP N SALARY FROM EMPLOYEE ORDER BY SALARY DESC)
---------------------------
SELECT MIN(SALARY) FROM EMPLOYEE
WHERE SALARY IN (SELECT DISTINCT TOP N SALARY FROM EMPLOYEE ORDER BY SALARY DESC)
---------------------------
Using SQL Server's CHARINDEX and PATINDEX
If you have written many applications then you probably have run across situations where you need to identify if a specific character or set of characters appears in a string. In this article I will discuss using the CHARINDEX and PATINDEX functions to search text columns and character strings. I will show you how each of these functions operate, and explain the differences between them. Also provided are some examples on how you might consider using these functions to solve a number of different character search situations.
The CHARINDEX and PATINDEX functions are used to search a character string for a character or set of characters. If the character string being searched contains the characters being searched for, then these functions return a non-zero integer value. This integer value is the starting location of where the character string being searched for is located within the string being searched. The PATINDEX function allows for using wildcard syntax in the pattern being searched for, where as the CHARINDEX function does not support wildcard character searches. Let's look at each one of these functions in a little more detail.
How to use the CHARINDEX Function
The CHARINDEX function returns the starting position of a character, or a string of characters within another character string. The CHARINDEX function is called using the following format:
CHARINDEX ( expression1 , expression2 [ , start_location ] )
Where expression1 is the string of characters to be found in expression2, and start_location is the position where the CHARINDEX function will start looking for expression1 in expression2.
The CHARINDEX function returns an integer. The integer value returned is the position where the characters being search for are located within the string being searched. If the CHARINDEX does not find the characters you are searching for then the function returns a zero integer value. Let say we execute the following CHARINDEX function call:
CHARINDEX('SQL', 'Microsoft SQL Server')
This function call will return the starting location of the character string "SQL", in the string "Microsoft SQL Server". In this case the CHARINDEX function will return the number 11, which as you can see is the starting position of "S" in string "Microsoft SQL Server".
Now say we have the following CHARINDEX Command:
CHARINDEX('7.0', 'Microsoft SQL Server 2000')
In this example the CHARINDEX function will return zero, since the character string "7.0" cannot be found in the string "Microsoft SQL Server 2000". Let go through a couple of examples of how you might be able to use the CHARINDEX function to solve some actual T-SQL problems.
For the first example say you would like to display only the last name of the ContactName column, for the first 5 records in the Northwind database Customer table. Here are the first 5 records.
ContactName
------------------------------
Maria Anders
Ana Trujillo
Antonio Moreno
Thomas Hardy
Christina Berglund
As you can see, the CustomerName contains both the first and last name of the customer, where first and last name are separated by a single space. I will use the CHARINDEX function to identify the position of the space between the two names. This way we can used the position of the space to parse the ContactName so we can display only the last name portion of the column. Here is some T-SQL code to display only the last name for the first 5 records in the Northwind Customer table.
select top 5 substring(ContactName,
charindex(' ',ContactName)+1 ,
len(ContactName)) as [Last Name]
from Northwind.dbo.customers
Here is the output from this command:
Last Name
------------------------------
Anders
Trujillo
Moreno
Hardy
Berglund
The CHARINDEX function found the space between the First and Last Name, so that the substring function could split the ContactName, thus only the Last Name was displayed. I added 1 to the integer value that CHARINDEX returned, so the Last Name displayed did not start with a space.
For the second example, say you want to count all the records from a table where a given column contains a particular character string. The CHARINDEX function could be used to satisfy your request. To count all of the Addresses in the Northwind.dbo.Customer table where the Address column contains either the word 'Road' or an abbreviation for road ('Rd'), your SELECT statement would look like this:
select count(*) from Northwind.dbo.Customers
where CHARINDEX('Rd',Address) > 0 or CHARINDEX('Road',Address)
> 1
How Does the PATINDEX Function Work?
The PATINDEX function returns the starting position of a character or string of characters within another string, or expression. As stated earlier the PATINDEX has additional functionality over CHARINDEX. PATINDEX supports wildcard characters in the search pattern string. This makes PATINDEX valuable for searching for varying string patterns. The PATINDEX command takes the following form:
PATINDEX ( '%pattern%' , expression )
Where "pattern" is the character string you are searching for and expression is the string in which you are searching. Commonly the expression is a column in a table. The "%" sign is needed on the front and back of the pattern, unless you are searching for the pattern at the beginning and/or ending of the expression.
Like the CHARINDEX function, the PATINDEX function returns the starting position of the pattern within the string being searched. If you have a PATINDEX function call like so:
PATINDEX('%BC%','ABCD')
Then the result of the PATINDEX function call is 2, which is the same as the CHARINDEX function. The %'s in the above command tells the PATINDEX command to find the position of the "BC" string where the string might have zero or more characters in front of, or after "BC". The % sign is a wildcard character.
If you want to determine if a string starts with a specific set of characters you would leave off the first % sign, and your PATINDEX call would look like this:
PATINDEX('AB%','ABCD')
In this case the PATINDEX function returns a 1, indicating that the pattern 'AB' was found in the expression 'ABCD'.
Now with wildcard characters you can create a much more complicated pattern matching situation then the simple ones I have shown you so far. Say you want to determine if a character string contains the letters A and Z, as well as any numeric number. Then your PATINDEX function call might look like this.
PATINDEX('%[A,Z,0-9]%[A,Z,0-9]%[A,Z,0-9]%','XYZABC123')
Note that the pattern I am looking for in the above example uses a number of wildcard references. Review SQL Server Books Online for other wildcard syntax information. Let's go through a couple of examples in how we might use the PATINDEX command in conjunction with a SELECT statement.
Say you want to find all of the records that contain the words "Bread", or "bread" in the Description text column in the Northwind.dbo.Categories table, then your select statement would look like this:
select Description from Northwind.dbo.Categories
where patindex('%[b,B]read%',description) > 0
Here I used wildcarding to look for either a lower or upper case "b". When I run this SELECT statement against my Northwind database I get the following Description columns displayed:
Description
--------------------------------------------------------
Desserts, candies, and sweet breads
Breads, crackers, pasta, and cereal
Here is another example where I used some additional wildcard references to find some records. This example excludes the Description that has an 'e' as the second letter from the result set in the above example.
select Description from Northwind.dbo.Categories
where patindex('%[b,B]read%',description) > 0
and patindex('_[^e]%',description) = 1
By adding an additional PATINDEX function call, to the where statement, that used the ^ wildcard symbol, I was able to exclude the "Dessert, candies, and sweet breads" description. The above example returned the following single description.
Description
--------------------------------------------------------
Breads, crackers, pasta, and cereal
Conclusion
As you can see the CHARINDEX and the PATINDEX perform similar kinds of pattern searches within a character string. The PATINDEX function provides wildcard specifications, allowing it to be used for much different kinds of pattern matches, while the CHARINDEX function does not. Depending on what you need to do, these two functions are great in helping you search, manipulate and parse character strings in SQL Server.
The CHARINDEX and PATINDEX functions are used to search a character string for a character or set of characters. If the character string being searched contains the characters being searched for, then these functions return a non-zero integer value. This integer value is the starting location of where the character string being searched for is located within the string being searched. The PATINDEX function allows for using wildcard syntax in the pattern being searched for, where as the CHARINDEX function does not support wildcard character searches. Let's look at each one of these functions in a little more detail.
How to use the CHARINDEX Function
The CHARINDEX function returns the starting position of a character, or a string of characters within another character string. The CHARINDEX function is called using the following format:
CHARINDEX ( expression1 , expression2 [ , start_location ] )
Where expression1 is the string of characters to be found in expression2, and start_location is the position where the CHARINDEX function will start looking for expression1 in expression2.
The CHARINDEX function returns an integer. The integer value returned is the position where the characters being search for are located within the string being searched. If the CHARINDEX does not find the characters you are searching for then the function returns a zero integer value. Let say we execute the following CHARINDEX function call:
CHARINDEX('SQL', 'Microsoft SQL Server')
This function call will return the starting location of the character string "SQL", in the string "Microsoft SQL Server". In this case the CHARINDEX function will return the number 11, which as you can see is the starting position of "S" in string "Microsoft SQL Server".
Now say we have the following CHARINDEX Command:
CHARINDEX('7.0', 'Microsoft SQL Server 2000')
In this example the CHARINDEX function will return zero, since the character string "7.0" cannot be found in the string "Microsoft SQL Server 2000". Let go through a couple of examples of how you might be able to use the CHARINDEX function to solve some actual T-SQL problems.
For the first example say you would like to display only the last name of the ContactName column, for the first 5 records in the Northwind database Customer table. Here are the first 5 records.
ContactName
------------------------------
Maria Anders
Ana Trujillo
Antonio Moreno
Thomas Hardy
Christina Berglund
As you can see, the CustomerName contains both the first and last name of the customer, where first and last name are separated by a single space. I will use the CHARINDEX function to identify the position of the space between the two names. This way we can used the position of the space to parse the ContactName so we can display only the last name portion of the column. Here is some T-SQL code to display only the last name for the first 5 records in the Northwind Customer table.
select top 5 substring(ContactName,
charindex(' ',ContactName)+1 ,
len(ContactName)) as [Last Name]
from Northwind.dbo.customers
Here is the output from this command:
Last Name
------------------------------
Anders
Trujillo
Moreno
Hardy
Berglund
The CHARINDEX function found the space between the First and Last Name, so that the substring function could split the ContactName, thus only the Last Name was displayed. I added 1 to the integer value that CHARINDEX returned, so the Last Name displayed did not start with a space.
For the second example, say you want to count all the records from a table where a given column contains a particular character string. The CHARINDEX function could be used to satisfy your request. To count all of the Addresses in the Northwind.dbo.Customer table where the Address column contains either the word 'Road' or an abbreviation for road ('Rd'), your SELECT statement would look like this:
select count(*) from Northwind.dbo.Customers
where CHARINDEX('Rd',Address) > 0 or CHARINDEX('Road',Address)
> 1
How Does the PATINDEX Function Work?
The PATINDEX function returns the starting position of a character or string of characters within another string, or expression. As stated earlier the PATINDEX has additional functionality over CHARINDEX. PATINDEX supports wildcard characters in the search pattern string. This makes PATINDEX valuable for searching for varying string patterns. The PATINDEX command takes the following form:
PATINDEX ( '%pattern%' , expression )
Where "pattern" is the character string you are searching for and expression is the string in which you are searching. Commonly the expression is a column in a table. The "%" sign is needed on the front and back of the pattern, unless you are searching for the pattern at the beginning and/or ending of the expression.
Like the CHARINDEX function, the PATINDEX function returns the starting position of the pattern within the string being searched. If you have a PATINDEX function call like so:
PATINDEX('%BC%','ABCD')
Then the result of the PATINDEX function call is 2, which is the same as the CHARINDEX function. The %'s in the above command tells the PATINDEX command to find the position of the "BC" string where the string might have zero or more characters in front of, or after "BC". The % sign is a wildcard character.
If you want to determine if a string starts with a specific set of characters you would leave off the first % sign, and your PATINDEX call would look like this:
PATINDEX('AB%','ABCD')
In this case the PATINDEX function returns a 1, indicating that the pattern 'AB' was found in the expression 'ABCD'.
Now with wildcard characters you can create a much more complicated pattern matching situation then the simple ones I have shown you so far. Say you want to determine if a character string contains the letters A and Z, as well as any numeric number. Then your PATINDEX function call might look like this.
PATINDEX('%[A,Z,0-9]%[A,Z,0-9]%[A,Z,0-9]%','XYZABC123')
Note that the pattern I am looking for in the above example uses a number of wildcard references. Review SQL Server Books Online for other wildcard syntax information. Let's go through a couple of examples in how we might use the PATINDEX command in conjunction with a SELECT statement.
Say you want to find all of the records that contain the words "Bread", or "bread" in the Description text column in the Northwind.dbo.Categories table, then your select statement would look like this:
select Description from Northwind.dbo.Categories
where patindex('%[b,B]read%',description) > 0
Here I used wildcarding to look for either a lower or upper case "b". When I run this SELECT statement against my Northwind database I get the following Description columns displayed:
Description
--------------------------------------------------------
Desserts, candies, and sweet breads
Breads, crackers, pasta, and cereal
Here is another example where I used some additional wildcard references to find some records. This example excludes the Description that has an 'e' as the second letter from the result set in the above example.
select Description from Northwind.dbo.Categories
where patindex('%[b,B]read%',description) > 0
and patindex('_[^e]%',description) = 1
By adding an additional PATINDEX function call, to the where statement, that used the ^ wildcard symbol, I was able to exclude the "Dessert, candies, and sweet breads" description. The above example returned the following single description.
Description
--------------------------------------------------------
Breads, crackers, pasta, and cereal
Conclusion
As you can see the CHARINDEX and the PATINDEX perform similar kinds of pattern searches within a character string. The PATINDEX function provides wildcard specifications, allowing it to be used for much different kinds of pattern matches, while the CHARINDEX function does not. Depending on what you need to do, these two functions are great in helping you search, manipulate and parse character strings in SQL Server.
Practical Uses of PatIndex() ... Or Why CharIndex() is not enough
PatIndex vs. CharIndex
One question that I am frequently asked by developers new to T-SQL is whether they should use CharIndex() or PatIndex() and what the difference between the two is. SQL Server Books Online explains that the difference between the two is that PatIndex can use wildcard characters. This is often unclear to many developers because they associate the term wildcard with the percent sign (%) only. What Books Online does not make clear is that PatIndex() can make use of the full spectrum of wildcard characters. This gives it power well beyond that of CharIndex().
PatIndex is Like Like
To really see the full capability of PatIndex(), you must take a look at the Like command in SQL Server Books Online. Books Online describes the available wildcards characters as follows:
Wildcard character Description Example
% Any string of zero or more characters. WHERE title LIKE '%computer%' finds all book titles with the word 'computer' anywhere in the book title.
_ (underscore) Any single character. WHERE au_fname LIKE '_ean' finds all four-letter first names that end with ean (Dean, Sean, and so on).
[ ] Any single character within the specified range ([a-f]) or set ([abcdef]). WHERE au_lname LIKE '[C-P]arsen' finds author last names ending with arsen and beginning with any single character between C and P, for example Carsen, Larsen, Karsen, and so on.
[^] Any single character not within the specified range ([^a-f]) or set ([^abcdef]). WHERE au_lname LIKE 'de[^l]%' all author last names beginning with de and where the following letter is not l.
If we adapt this table for PatIndex(), it would look something like this:
Wildcard character Description Example
% Any string of zero or more characters. WHERE PatIndex('%computer%', title) > 0 finds all book titles with the word 'computer' anywhere in the book title.
_ (underscore) Any single character. WHERE PatIndex('_ean', au_fname) > 0 finds all four-letter first names that end with ean (Dean, Sean, and so on).
[ ] Any single character within the specified range ([a-f]) or set ([abcdef]). WHERE PatIndex('[C-P]arsen', au_lname) > 0 finds author last names ending with arsen and beginning with any single character between C and P (Carsen, Larsen, Karsen, and so on).
[^] Any single character not within the specified range ([^a-f]) or set ([^abcdef]). WHERE PatIndex('de[^l]%', au_lname) > 0 finds all author last names beginning with de and where the following letter is not l (finds Derry but not Delton).
Let's Get Practical
Let's take a real world example. If we have a varchar field that may contain non-numeric data and we want to Select the records and include the data in this field if it contains numbers only and nothing else, we can use PatIndex().
Background:
As the DBA for my company, my team supports all database needs for our company's applications including a web application. A key data field within this application is the customer's internal company ID for their employees. Since this ID is defined by the client, we must allow the use of alpha-numeric codes. A separate customer driven project calls for us to export their roster data to send to a third party. One of the requirements of the project is that if an employee's company ID contains data other than a number, we should assume that the value is incorrect and not include it.
Solution:
I decided to use PatIndex() in a Case statement with the not within a range wildcards. The range in this case would be 0 to 9 ( [0-9] ), and I would express not within this range by using the expression [^0-9]. My resulting Case statement looks like:
CompanyID = Case When PatIndex('%[^0-9]%', IsNull(CompanyID, '*')) > 0 Then Null Else CompanyID End
Going a little further:
If I want to go a little further with this concept, I could write a User-Defined Function ( named fnIsInt()) that accepts a varchar value and returns a 0 or a 1 indicating if the value could be converted to an integer data type as is without any other string manipulation. This function would work much like the built-in IsNumeric() function. The difference between the two functions is that IsNumeric() allows additional characters such as the decimal point, currency symbols, commas.
Since this article is focusing on practical uses of PatIndex, I will only be checking to see if the string value contains digits only with the exception of allowing it to begin with a negative sign. I will not include checking to see if the value is within the allowable range of the Int data type.
Create Function dbo.fnIsInt(
@value varchar(11))
Returns int
As
Begin
Declare @IsInt int
Set @IsInt = 0
If PatIndex('%[^0-9]%', @value) > 0 Or PatIndex('-%[^0-9]%', @value) > 0
Begin
Set @IsInt = 0
End
Else
Begin
Set @IsInt = 1
End
Return @IsInt
End
Testing the function:
Select IsNumeric('4'), PatIndex('%[^0-9]%', '4'), dbo.fnIsInt('4')
----------- ----------- -----------
1 0 1
Select IsNumeric('4.2'), PatIndex('%[^0-9]%', '4.2'), dbo.fnIsInt('4.2')
----------- ----------- -----------
1 2 0
Select IsNumeric('4-2'), PatIndex('%[^0-9]%', '4-2'), dbo.fnIsInt('4-2')
----------- ----------- -----------
0 2 0
Select IsNumeric('-4'), PatIndex('%[^0-9]%', '-4'), dbo.fnIsInt('-4')
----------- ----------- -----------
1 1 0
Select IsNumeric('4,2'), PatIndex('%[^0-9]%', '4,2'), dbo.fnIsInt('4,2')
----------- ----------- -----------
1 2 0
Select IsNumeric('$42'), PatIndex('%[^0-9]%', '$42'), dbo.fnIsInt('$42')
----------- ----------- -----------
1 1 0
The Big Deal?
Okay, I admit that I could have done the above Case statement just as easily using Like commands. Since I did not need to know the position of the offending characters, PatIndex() was more than was needed for that situation. If the project had required that I remove the non-digit characters rather than simply returning Null, PatIndex() would have been the perfect solution.
I can easily leverage the full power of PatIndex() by creating a User-Defined Function that accepts a varchar value and returns a varchar value with all non-digit characters removed.
Create Function dbo.fnDigitsOnly(
@value varchar(50))
Returns varchar(50)
As
Begin
If PatIndex('%[^0-9]%', @value) > 0
Begin
While PatIndex('%[^0-9]%', @value) > 0
Begin
Set @value = Stuff(@value, PatIndex('%[^0-9]%', @value), 1, '')
End
End
Return @value
End
The Big Finish
So, what's the difference between CharIndex() and PatIndex()? Well, like Books Online says, PatIndex() can use wildcards. To put it as simple as I can, PatIndex() combines the capabilities of the CharIndex() function and the Like command. 99.99% of the time, CharIndex() and PatIndex() are used interchangeably. That 0.01% of the time that you need something more, you'll be glad to have PatIndex() in your T-SQL toolbox.
One question that I am frequently asked by developers new to T-SQL is whether they should use CharIndex() or PatIndex() and what the difference between the two is. SQL Server Books Online explains that the difference between the two is that PatIndex can use wildcard characters. This is often unclear to many developers because they associate the term wildcard with the percent sign (%) only. What Books Online does not make clear is that PatIndex() can make use of the full spectrum of wildcard characters. This gives it power well beyond that of CharIndex().
PatIndex is Like Like
To really see the full capability of PatIndex(), you must take a look at the Like command in SQL Server Books Online. Books Online describes the available wildcards characters as follows:
Wildcard character Description Example
% Any string of zero or more characters. WHERE title LIKE '%computer%' finds all book titles with the word 'computer' anywhere in the book title.
_ (underscore) Any single character. WHERE au_fname LIKE '_ean' finds all four-letter first names that end with ean (Dean, Sean, and so on).
[ ] Any single character within the specified range ([a-f]) or set ([abcdef]). WHERE au_lname LIKE '[C-P]arsen' finds author last names ending with arsen and beginning with any single character between C and P, for example Carsen, Larsen, Karsen, and so on.
[^] Any single character not within the specified range ([^a-f]) or set ([^abcdef]). WHERE au_lname LIKE 'de[^l]%' all author last names beginning with de and where the following letter is not l.
If we adapt this table for PatIndex(), it would look something like this:
Wildcard character Description Example
% Any string of zero or more characters. WHERE PatIndex('%computer%', title) > 0 finds all book titles with the word 'computer' anywhere in the book title.
_ (underscore) Any single character. WHERE PatIndex('_ean', au_fname) > 0 finds all four-letter first names that end with ean (Dean, Sean, and so on).
[ ] Any single character within the specified range ([a-f]) or set ([abcdef]). WHERE PatIndex('[C-P]arsen', au_lname) > 0 finds author last names ending with arsen and beginning with any single character between C and P (Carsen, Larsen, Karsen, and so on).
[^] Any single character not within the specified range ([^a-f]) or set ([^abcdef]). WHERE PatIndex('de[^l]%', au_lname) > 0 finds all author last names beginning with de and where the following letter is not l (finds Derry but not Delton).
Let's Get Practical
Let's take a real world example. If we have a varchar field that may contain non-numeric data and we want to Select the records and include the data in this field if it contains numbers only and nothing else, we can use PatIndex().
Background:
As the DBA for my company, my team supports all database needs for our company's applications including a web application. A key data field within this application is the customer's internal company ID for their employees. Since this ID is defined by the client, we must allow the use of alpha-numeric codes. A separate customer driven project calls for us to export their roster data to send to a third party. One of the requirements of the project is that if an employee's company ID contains data other than a number, we should assume that the value is incorrect and not include it.
Solution:
I decided to use PatIndex() in a Case statement with the not within a range wildcards. The range in this case would be 0 to 9 ( [0-9] ), and I would express not within this range by using the expression [^0-9]. My resulting Case statement looks like:
CompanyID = Case When PatIndex('%[^0-9]%', IsNull(CompanyID, '*')) > 0 Then Null Else CompanyID End
Going a little further:
If I want to go a little further with this concept, I could write a User-Defined Function ( named fnIsInt()) that accepts a varchar value and returns a 0 or a 1 indicating if the value could be converted to an integer data type as is without any other string manipulation. This function would work much like the built-in IsNumeric() function. The difference between the two functions is that IsNumeric() allows additional characters such as the decimal point, currency symbols, commas.
Since this article is focusing on practical uses of PatIndex, I will only be checking to see if the string value contains digits only with the exception of allowing it to begin with a negative sign. I will not include checking to see if the value is within the allowable range of the Int data type.
Create Function dbo.fnIsInt(
@value varchar(11))
Returns int
As
Begin
Declare @IsInt int
Set @IsInt = 0
If PatIndex('%[^0-9]%', @value) > 0 Or PatIndex('-%[^0-9]%', @value) > 0
Begin
Set @IsInt = 0
End
Else
Begin
Set @IsInt = 1
End
Return @IsInt
End
Testing the function:
Select IsNumeric('4'), PatIndex('%[^0-9]%', '4'), dbo.fnIsInt('4')
----------- ----------- -----------
1 0 1
Select IsNumeric('4.2'), PatIndex('%[^0-9]%', '4.2'), dbo.fnIsInt('4.2')
----------- ----------- -----------
1 2 0
Select IsNumeric('4-2'), PatIndex('%[^0-9]%', '4-2'), dbo.fnIsInt('4-2')
----------- ----------- -----------
0 2 0
Select IsNumeric('-4'), PatIndex('%[^0-9]%', '-4'), dbo.fnIsInt('-4')
----------- ----------- -----------
1 1 0
Select IsNumeric('4,2'), PatIndex('%[^0-9]%', '4,2'), dbo.fnIsInt('4,2')
----------- ----------- -----------
1 2 0
Select IsNumeric('$42'), PatIndex('%[^0-9]%', '$42'), dbo.fnIsInt('$42')
----------- ----------- -----------
1 1 0
The Big Deal?
Okay, I admit that I could have done the above Case statement just as easily using Like commands. Since I did not need to know the position of the offending characters, PatIndex() was more than was needed for that situation. If the project had required that I remove the non-digit characters rather than simply returning Null, PatIndex() would have been the perfect solution.
I can easily leverage the full power of PatIndex() by creating a User-Defined Function that accepts a varchar value and returns a varchar value with all non-digit characters removed.
Create Function dbo.fnDigitsOnly(
@value varchar(50))
Returns varchar(50)
As
Begin
If PatIndex('%[^0-9]%', @value) > 0
Begin
While PatIndex('%[^0-9]%', @value) > 0
Begin
Set @value = Stuff(@value, PatIndex('%[^0-9]%', @value), 1, '')
End
End
Return @value
End
The Big Finish
So, what's the difference between CharIndex() and PatIndex()? Well, like Books Online says, PatIndex() can use wildcards. To put it as simple as I can, PatIndex() combines the capabilities of the CharIndex() function and the Like command. 99.99% of the time, CharIndex() and PatIndex() are used interchangeably. That 0.01% of the time that you need something more, you'll be glad to have PatIndex() in your T-SQL toolbox.
Attach Database or Detach Database with SP
Introduction
If you need to move a database, or database file to another server or disk, and you do not want to backup the database, copy the backup on another server, and then re-create database from the backup, you can use the sp_detach_db and sp_attach_db system stored procedures to detach database and then attach it again. Detaching and attaching databases can be used when you want to move the database files to a different physical disk from the disk that run out of disk space and you want to expand the existing file rather than add a new file to the database on another disk.
To move a database using detach and attach, you should make the following steps:
• Detach the database.
• Move the database file(s) to the desired location on another server or disk.
• Attach the database specifying the new location of the moved file(s).
After detaching, the database will be removed from SQL Server but will be intact within the data and transaction log files that compose the database. You can use these data and transaction log files to attach the database to any instance of SQL Server, including the server from which the database was detached. After attaching, the database will be available in exactly the same state it was in when it was detached.
Detaching a DatabaseTo detach an SQL Server 2000 database, you can use the sp_detach_db system stored procedure. This stored procedure can also run UPDATE STATISTICS on all tables before detaching. The syntax for sp_detach_db system stored procedure is as follows:
sp_detach_db [ @dbname = ] 'dbname'
[ , [ @skipchecks = ] 'skipchecks' ]
In the above, the parameters to the stored procedure are as follows:
• [@dbname =] 'dbname' is the database name. 'dbname'is nvarchar(128), a default value is NULL.
• [@skipchecks =] 'skipchecks' The 'skipchecks' parameter indicates will be can UPDATE STATISTICS run or skipped. The 'skipchecks' is nvarchar(10), a default value is NULL. If 'skipchecks' is true, UPDATE STATISTICS is skipped. If 'skipchecks' is false, UPDATE STATISTICS is run.
The following example detaches the pubs database and run UPDATE STATISTICS on all tables before detaching:
EXEC sp_detach_db 'pubs', 'false'
Attaching a DatabaseWhen you attach a database, you must specify at least the name and physical location of the primary data file. If one or more of database files have changed location since the database was detached, you must specify the name and physical location of these files in addition to the primary file.
To attach SQL Server 2000 database, you can use the sp_attach_db system stored procedure. The syntax for sp_attach_db system stored procedure is as follows:
sp_attach_db [ @dbname = ] 'dbname',
[ @filename1 = ] 'filename_n' [ ,...16 ]
In the above command:
• [@dbname =] 'dbname'is the database name. dbname is nvarchar(128), a default value is NULL.
• [@filename1 =] 'filename_n'Is the database file name. filename_n is nvarchar(260), a default value is NULL. There can be up to 16 file names specified.
This is the example to attach the pubs database which contain two files pubs.mdf and pubs_log.ldf from the C:\MSSQL\Data directory:
EXEC sp_attach_db @dbname = 'pubs',
@filename1 = 'C:\MSSQL\Data\pubs.mdf',
@filename2 = 'C:\MSSQL\Data\pubs_log.ldf'
Attaching a Single-File DatabaseA single-file database is a database that have only one data file. When a database comprises only one data file, the database can be attached to an instance of SQL Server 2000 without using the transaction log file. When the data file will be attached, SQL Server will create a new transaction log file automatically.
To attach a single-file database, you can use the sp_attach_single_file_db system stored procedure. The syntax for sp_attach_single_file_db system stored procedure is as follows:
sp_attach_single_file_db [ @dbname = ] 'dbname'
, [ @physname = ] 'physical_name'
• [@dbname =] 'dbname' is the database name. 'dbname' is nvarchar(128), a default value is NULL.
• [@physname =] 'phsyical_name' is the database file name. 'phsyical_name' is nvarchar(260), a default value is NULL.
This is the example to attach only one data file of the pubs database from the C:\MSSQL\Data directory:
EXEC sp_attach_single_file_db @dbname = 'pubs',
@physname = 'C:\MSSQL\Data\pubs.mdf'
Troubleshooting Lost UsersWhen you move database to another server and there are existing users in the detached database, you can lose users after attaching database on the new server. For example, if you move the Sales database from the Product server to the Test server (for the test purposes) and the user Alex exists in the Sales database, you should manually link the relationship between the Alex user and the appropriate login on the Test server.
You can use the sp_change_users_login system stored procedure to link the specified user in the current database to the appropriate login. The following example links the user Alex in the current database to t he Alex login:
EXEC sp_change_users_login 'Update_One', 'Alex', 'Alex'
See SQL Server Books Online to get more information about the sp_change_users_login stored procedure.
If you need to move a database, or database file to another server or disk, and you do not want to backup the database, copy the backup on another server, and then re-create database from the backup, you can use the sp_detach_db and sp_attach_db system stored procedures to detach database and then attach it again. Detaching and attaching databases can be used when you want to move the database files to a different physical disk from the disk that run out of disk space and you want to expand the existing file rather than add a new file to the database on another disk.
To move a database using detach and attach, you should make the following steps:
• Detach the database.
• Move the database file(s) to the desired location on another server or disk.
• Attach the database specifying the new location of the moved file(s).
After detaching, the database will be removed from SQL Server but will be intact within the data and transaction log files that compose the database. You can use these data and transaction log files to attach the database to any instance of SQL Server, including the server from which the database was detached. After attaching, the database will be available in exactly the same state it was in when it was detached.
Detaching a DatabaseTo detach an SQL Server 2000 database, you can use the sp_detach_db system stored procedure. This stored procedure can also run UPDATE STATISTICS on all tables before detaching. The syntax for sp_detach_db system stored procedure is as follows:
sp_detach_db [ @dbname = ] 'dbname'
[ , [ @skipchecks = ] 'skipchecks' ]
In the above, the parameters to the stored procedure are as follows:
• [@dbname =] 'dbname' is the database name. 'dbname'is nvarchar(128), a default value is NULL.
• [@skipchecks =] 'skipchecks' The 'skipchecks' parameter indicates will be can UPDATE STATISTICS run or skipped. The 'skipchecks' is nvarchar(10), a default value is NULL. If 'skipchecks' is true, UPDATE STATISTICS is skipped. If 'skipchecks' is false, UPDATE STATISTICS is run.
The following example detaches the pubs database and run UPDATE STATISTICS on all tables before detaching:
EXEC sp_detach_db 'pubs', 'false'
Attaching a DatabaseWhen you attach a database, you must specify at least the name and physical location of the primary data file. If one or more of database files have changed location since the database was detached, you must specify the name and physical location of these files in addition to the primary file.
To attach SQL Server 2000 database, you can use the sp_attach_db system stored procedure. The syntax for sp_attach_db system stored procedure is as follows:
sp_attach_db [ @dbname = ] 'dbname',
[ @filename1 = ] 'filename_n' [ ,...16 ]
In the above command:
• [@dbname =] 'dbname'is the database name. dbname is nvarchar(128), a default value is NULL.
• [@filename1 =] 'filename_n'Is the database file name. filename_n is nvarchar(260), a default value is NULL. There can be up to 16 file names specified.
This is the example to attach the pubs database which contain two files pubs.mdf and pubs_log.ldf from the C:\MSSQL\Data directory:
EXEC sp_attach_db @dbname = 'pubs',
@filename1 = 'C:\MSSQL\Data\pubs.mdf',
@filename2 = 'C:\MSSQL\Data\pubs_log.ldf'
Attaching a Single-File DatabaseA single-file database is a database that have only one data file. When a database comprises only one data file, the database can be attached to an instance of SQL Server 2000 without using the transaction log file. When the data file will be attached, SQL Server will create a new transaction log file automatically.
To attach a single-file database, you can use the sp_attach_single_file_db system stored procedure. The syntax for sp_attach_single_file_db system stored procedure is as follows:
sp_attach_single_file_db [ @dbname = ] 'dbname'
, [ @physname = ] 'physical_name'
• [@dbname =] 'dbname' is the database name. 'dbname' is nvarchar(128), a default value is NULL.
• [@physname =] 'phsyical_name' is the database file name. 'phsyical_name' is nvarchar(260), a default value is NULL.
This is the example to attach only one data file of the pubs database from the C:\MSSQL\Data directory:
EXEC sp_attach_single_file_db @dbname = 'pubs',
@physname = 'C:\MSSQL\Data\pubs.mdf'
Troubleshooting Lost UsersWhen you move database to another server and there are existing users in the detached database, you can lose users after attaching database on the new server. For example, if you move the Sales database from the Product server to the Test server (for the test purposes) and the user Alex exists in the Sales database, you should manually link the relationship between the Alex user and the appropriate login on the Test server.
You can use the sp_change_users_login system stored procedure to link the specified user in the current database to the appropriate login. The following example links the user Alex in the current database to t he Alex login:
EXEC sp_change_users_login 'Update_One', 'Alex', 'Alex'
See SQL Server Books Online to get more information about the sp_change_users_login stored procedure.
Monday, April 17, 2006
SQL Server Replication Part 1
SQL Server replication
SQL Server replication allows database administrators to distribute data to various servers throughout an organization. You may wish to implement replication in your organization for a number of reasons, such as:
Load balancing. Replication allows you to disseminate your data to a number of servers and then distribute the query load among those servers.
Offline processing. You may wish to manipulate data from your database on a machine that is not always connected to the network.
Redundancy. Replication allows you to build a fail-over database server that’s ready to pick up the processing load at a moment’s notice.
In any replication scenario, there are 3 main components:
Publishers have data to offer to other servers. Any given replication scheme may have one or more publishers.
Distributor maintains the Distribution Database. The role of the distributor varies depending on the type of replication. Two types of Distributors are identified, remote distributor and Local distributor. Remote distributor is separate from publisher and is configured as distributor for replication. Local distributor is a server that is configured as publisher and distributor.
Subscribers are database servers that wish to receive updates from the Publisher when data is modified.
There’s nothing preventing a single system from acting in both of these capacities. In fact, this is often done in large-scale distributed database systems. Microsoft SQL Server supports three types of database replication. This article provides a brief introduction to each of these models, while future articles will explore them in further detail. They are:
Snapshot replication acts in the manner its name implies. The publisher simply takes a snapshot of the entire replicated database and shares it with the subscribers. Of course, this is a very time and resource-intensive process. For this reason, most administrators don’t use snapshot replication on a recurring basis for databases that change frequently. There are two scenarios where snapshot replication is commonly used. First, it is used for databases that rarely change. Second, it is used to set a baseline to establish replication between systems while future updates are propagated using transactional or merge replication.
Transactional replication offers a more flexible solution for databases that change on a regular basis. With transactional replication, the replication agent monitors the publisher for changes to the database and transmits those changes to the subscribers. This transmission can take place immediately or on a periodic basis.
Merge replication allows the publisher and subscriber to independently make changes to the database. Both entities can work without an active network connection. When they are reconnected, the merge replication agent checks for changes on both sets of data and modifies each database accordingly. If changes conflict with each other, it uses a predefined conflict resolution algorithm to determine the appropriate data. Merge replication is commonly used by laptop users and others who can not be constantly connected to the publisher.
SQL Server replication allows database administrators to distribute data to various servers throughout an organization. You may wish to implement replication in your organization for a number of reasons, such as:
Load balancing. Replication allows you to disseminate your data to a number of servers and then distribute the query load among those servers.
Offline processing. You may wish to manipulate data from your database on a machine that is not always connected to the network.
Redundancy. Replication allows you to build a fail-over database server that’s ready to pick up the processing load at a moment’s notice.
In any replication scenario, there are 3 main components:
Publishers have data to offer to other servers. Any given replication scheme may have one or more publishers.
Distributor maintains the Distribution Database. The role of the distributor varies depending on the type of replication. Two types of Distributors are identified, remote distributor and Local distributor. Remote distributor is separate from publisher and is configured as distributor for replication. Local distributor is a server that is configured as publisher and distributor.
Subscribers are database servers that wish to receive updates from the Publisher when data is modified.
There’s nothing preventing a single system from acting in both of these capacities. In fact, this is often done in large-scale distributed database systems. Microsoft SQL Server supports three types of database replication. This article provides a brief introduction to each of these models, while future articles will explore them in further detail. They are:
Snapshot replication acts in the manner its name implies. The publisher simply takes a snapshot of the entire replicated database and shares it with the subscribers. Of course, this is a very time and resource-intensive process. For this reason, most administrators don’t use snapshot replication on a recurring basis for databases that change frequently. There are two scenarios where snapshot replication is commonly used. First, it is used for databases that rarely change. Second, it is used to set a baseline to establish replication between systems while future updates are propagated using transactional or merge replication.
Transactional replication offers a more flexible solution for databases that change on a regular basis. With transactional replication, the replication agent monitors the publisher for changes to the database and transmits those changes to the subscribers. This transmission can take place immediately or on a periodic basis.
Merge replication allows the publisher and subscriber to independently make changes to the database. Both entities can work without an active network connection. When they are reconnected, the merge replication agent checks for changes on both sets of data and modifies each database accordingly. If changes conflict with each other, it uses a predefined conflict resolution algorithm to determine the appropriate data. Merge replication is commonly used by laptop users and others who can not be constantly connected to the publisher.
What is a Correlated Subquery?
What is a Correlated Subquery?
A correlated subquery is a SELECT statement nested inside another T-SQL statement, which contains a reference to one or more columns in the outer query. Therefore, the correlated subquery can be said to be dependent on the outer query. This is the main difference between a correlated subquery and just a plain subquery. A plain subquery is not dependent on the outer query, can be run independently of the outer query, and will return a result set. A correlated subquery, since it is dependent on the outer query will return a syntax errors if it is run by itself.
A correlated subquery will be executed many times while processing the T-SQL statement that contains the correlated subquery. The correlated subquery will be run once for each candidate row selected by the outer query. The outer query columns, referenced in the correlated subquery, are replaced with values from the candidate row prior to each execution. Depending on the results of the execution of the correlated subquery, it will determine if the row of the outer query is returned in the final result set.
Using a Correlated Subquery in a WHERE Clause
Suppose you want a report of all "OrderID's" where the customer did not purchase more than 10% of the average quantity sold for a given product. This way you could review these orders, and possibly contact the customers, to help determine if there was a reason for the low quantity order. A correlated subquery in a WHERE clause can help you produce this report. Here is a SELECT statement that produces the desired list of "OrderID's":
select distinct OrderId from Northwind.dbo.[Order Details] OD
where Quantity
from Northwind.dbo.[Order Details]
where OD.ProductID = ProductID)
The correlated subquery in the above command is contained within the parenthesis following the greater than sign in the WHERE clause above. Here you can see this correlated subquery contains a reference to "OD.ProductID". This reference compares the outer query's "ProductID" with the inner query's "ProductID". When this query is executed, the SQL engine will execute the inner query, the correlated subquery, for each "[Order Details]" record. This inner query will calculate the average "Quantity" for the particular "ProductID" for the candidate row being processed in the outer query. This correlated subquery determines if the inner query returns a value that meets the condition of the WHERE clause. If it does, the row identified by the outer query is placed in the record set that will be returned from the complete T-SQL SELECT statement.
The code below is another example that uses a correlated subquery in the WHERE clause to display the top two customers, based on the dollar amount associated with their orders, per region. You might want to perform a query like this so you can reward these customers, since they buy the most per region.
select CompanyName, ContactName, Address, City, Country, PostalCode
from Northwind.dbo.Customers OuterCwhere CustomerID in
( select top 2 InnerC.CustomerId from Northwind.dbo.[Order Details] OD join Northwind.dbo.Orders O on OD.OrderId = O.OrderID join Northwind.dbo.Customers InnerC on O.CustomerID = InnerC.CustomerId Where Region = OuterC.Region
group by Region, InnerC.CustomerId
order by sum(UnitPrice * Quantity * (1-Discount)) desc ) order by Region
Here you can see the inner query is a correlated subquery because it references "OuterC", which is the table alias for the "Northwind.DBO.Customer" table in the outer query. This inner query uses the "Region" value to calculate the top two customers for the region associated with the row being processed from the outer query. If the "CustomerID" of the outer query is one of the top two customers, then the record is placed in the record set to be returned.
Correlated Subquery in the HAVING Clause
Say your organizations wants to run a yearlong incentive program to increase revenue. Therefore, they advertise to your customers that if each order they place, during the year, is over $750 you will provide them a rebate at the end of the year at the rate of $75 per order they place. Below is an example of how to calculate the rebate amount. This example uses a correlated subquery in the HAVING clause to identify the customers that qualify to receive the rebate. Here is my code for this query:
select C.CustomerID, Count(*)*75 Rebate from Northwind.DBO.Customers C join Northwind.DBO.Orders O on c.CustomerID = O.CustomerID where Datepart(yy,OrderDate) = '1998' group by C.CustomerId having 750 < orderid =" OD.OrderID" customerid =" C.CustomerId">
By reviewing this query, you can see I am using a correlated query in the HAVING clause to calculate the total order amount for each customer order. I use the "CustomerID" from the outer query and the year of the order "Datepart(yy,OrderDate)", to help identify the Order records associated with each customer, that were placed the year '1998'. For these associated records I am calculating the total order amount, for each order, by summing up all the "[Order Details]" records, using the following formula:
sum(UnitPrice * Quantity * (1-Discount)). If each and every order for a customer, for year 1998 has a total dollar amount greater than 750, I then calculate the Rebate amount in the outer query using this formula "Count(*)*75 ".
SQL Server's query engine will only execute the inner correlated subquery in the HAVING clause for those customer records identified in the outer query, or basically only those customer that placed orders in "1998".
Performing an Update Statement Using a Correlated Subquery
A correlated subquery can even be used in an update statement. Here is an example:
create table A(A int, S int)
create table B(A int, B int)
-----------
set nocount on
insert into A(A) values(1)
insert into A(A) values(2)
insert into A(A) values(3)
insert into B values(1,1)
insert into B values(2,1)
insert into B values(2,1)
insert into B values(3,1)
insert into B values(3,1)
insert into B values(3,1)
update A set S = (select sum(B) from B where A.A = A group by A)
-----------
select * from A
-----------
drop table A,B
Here is the result set I get when I run this query on my machine:
A S
----------- -----------
1 1
2 2
3 3
In my query above, I used the correlated subquery to update column A in table A with the sum of column B in table B for rows that have the same value in column A as the row being updated.
Correlated in Condition:
AND EXISTS (SELECT TOP 1 1 FROM Table1 where {expression})
(Taken From Databasejournal article by Gregory A. Larsen)
A correlated subquery is a SELECT statement nested inside another T-SQL statement, which contains a reference to one or more columns in the outer query. Therefore, the correlated subquery can be said to be dependent on the outer query. This is the main difference between a correlated subquery and just a plain subquery. A plain subquery is not dependent on the outer query, can be run independently of the outer query, and will return a result set. A correlated subquery, since it is dependent on the outer query will return a syntax errors if it is run by itself.
A correlated subquery will be executed many times while processing the T-SQL statement that contains the correlated subquery. The correlated subquery will be run once for each candidate row selected by the outer query. The outer query columns, referenced in the correlated subquery, are replaced with values from the candidate row prior to each execution. Depending on the results of the execution of the correlated subquery, it will determine if the row of the outer query is returned in the final result set.
Using a Correlated Subquery in a WHERE Clause
Suppose you want a report of all "OrderID's" where the customer did not purchase more than 10% of the average quantity sold for a given product. This way you could review these orders, and possibly contact the customers, to help determine if there was a reason for the low quantity order. A correlated subquery in a WHERE clause can help you produce this report. Here is a SELECT statement that produces the desired list of "OrderID's":
select distinct OrderId from Northwind.dbo.[Order Details] OD
where Quantity
from Northwind.dbo.[Order Details]
where OD.ProductID = ProductID)
The correlated subquery in the above command is contained within the parenthesis following the greater than sign in the WHERE clause above. Here you can see this correlated subquery contains a reference to "OD.ProductID". This reference compares the outer query's "ProductID" with the inner query's "ProductID". When this query is executed, the SQL engine will execute the inner query, the correlated subquery, for each "[Order Details]" record. This inner query will calculate the average "Quantity" for the particular "ProductID" for the candidate row being processed in the outer query. This correlated subquery determines if the inner query returns a value that meets the condition of the WHERE clause. If it does, the row identified by the outer query is placed in the record set that will be returned from the complete T-SQL SELECT statement.
The code below is another example that uses a correlated subquery in the WHERE clause to display the top two customers, based on the dollar amount associated with their orders, per region. You might want to perform a query like this so you can reward these customers, since they buy the most per region.
select CompanyName, ContactName, Address, City, Country, PostalCode
from Northwind.dbo.Customers OuterCwhere CustomerID in
( select top 2 InnerC.CustomerId from Northwind.dbo.[Order Details] OD join Northwind.dbo.Orders O on OD.OrderId = O.OrderID join Northwind.dbo.Customers InnerC on O.CustomerID = InnerC.CustomerId Where Region = OuterC.Region
group by Region, InnerC.CustomerId
order by sum(UnitPrice * Quantity * (1-Discount)) desc ) order by Region
Here you can see the inner query is a correlated subquery because it references "OuterC", which is the table alias for the "Northwind.DBO.Customer" table in the outer query. This inner query uses the "Region" value to calculate the top two customers for the region associated with the row being processed from the outer query. If the "CustomerID" of the outer query is one of the top two customers, then the record is placed in the record set to be returned.
Correlated Subquery in the HAVING Clause
Say your organizations wants to run a yearlong incentive program to increase revenue. Therefore, they advertise to your customers that if each order they place, during the year, is over $750 you will provide them a rebate at the end of the year at the rate of $75 per order they place. Below is an example of how to calculate the rebate amount. This example uses a correlated subquery in the HAVING clause to identify the customers that qualify to receive the rebate. Here is my code for this query:
select C.CustomerID, Count(*)*75 Rebate from Northwind.DBO.Customers C join Northwind.DBO.Orders O on c.CustomerID = O.CustomerID where Datepart(yy,OrderDate) = '1998' group by C.CustomerId having 750 < orderid =" OD.OrderID" customerid =" C.CustomerId">
By reviewing this query, you can see I am using a correlated query in the HAVING clause to calculate the total order amount for each customer order. I use the "CustomerID" from the outer query and the year of the order "Datepart(yy,OrderDate)", to help identify the Order records associated with each customer, that were placed the year '1998'. For these associated records I am calculating the total order amount, for each order, by summing up all the "[Order Details]" records, using the following formula:
sum(UnitPrice * Quantity * (1-Discount)). If each and every order for a customer, for year 1998 has a total dollar amount greater than 750, I then calculate the Rebate amount in the outer query using this formula "Count(*)*75 ".
SQL Server's query engine will only execute the inner correlated subquery in the HAVING clause for those customer records identified in the outer query, or basically only those customer that placed orders in "1998".
Performing an Update Statement Using a Correlated Subquery
A correlated subquery can even be used in an update statement. Here is an example:
create table A(A int, S int)
create table B(A int, B int)
-----------
set nocount on
insert into A(A) values(1)
insert into A(A) values(2)
insert into A(A) values(3)
insert into B values(1,1)
insert into B values(2,1)
insert into B values(2,1)
insert into B values(3,1)
insert into B values(3,1)
insert into B values(3,1)
update A set S = (select sum(B) from B where A.A = A group by A)
-----------
select * from A
-----------
drop table A,B
Here is the result set I get when I run this query on my machine:
A S
----------- -----------
1 1
2 2
3 3
In my query above, I used the correlated subquery to update column A in table A with the sum of column B in table B for rows that have the same value in column A as the row being updated.
Correlated in Condition:
AND EXISTS (SELECT TOP 1 1 FROM Table1 where {expression})
(Taken From Databasejournal article by Gregory A. Larsen)
Sunday, April 16, 2006
Using a Subquery in a T-SQL Statement !
What is a Subquery?
A subquery is a SELECT statement that is nested within another T-SQL statement. A subquery SELECT statement if executed independently of the T-SQL statement, in which it is nested, will return a result set. Meaning a subquery SELECT statement can standalone and is not depended on the statement in which it is nested. A subquery SELECT statement can return any number of values, and can be found in, the column list of a SELECT statement, a FROM, GROUP BY, HAVING, and/or ORDER BY clauses of a T-SQL statement. A Subquery can also be used as a parameter to a function call. Basically a subquery can be used anywhere an expression can be used.
Use of a Subquery in the Column List of a SELECT Statement
Suppose you would like to see the last OrderID and the OrderDate for the last order that was shipped to Paris. Along with that information, say you would also like to see the OrderDate for the last order shipped regardless of the ShipCity. In addition to this, you would also like to calculate the difference in days between the two different OrderDates. Here is my T-SQL SELECT statement to accomplish this:
The above code contains two subqueries. The first subquery gets the OrderDate for the last order shipped regardless of ShipCity, and the second subquery calculates the number of days between the two different OrderDates. Here I used the first subquery to return a column value in the final result set. The second subquery was used as a parameter in a function call. This subquery passed the "max(OrderDate)" date to the DATEDIFF function.
Here I have written a subquery that joins the Customer and Orders Tables to determine the total number of orders for each country. The subquery uses the "TOP 1" clause to return the country with the fewest number of orders. The country with the fewest number of orders is then used in the WHERE clause to determine which Customer Information will be displayed.
Use of a Subquery in the FROM clause
The FROM clause normally identifies the tables used in the T-SQL statement. You can think of each of the tables identified in the FROM clause as a set of records. Well, a subquery is just a set of records, and therefore can be used in the FROM clause just like a table. Here is an example where a subquery is used in the FROM clause of a SELECT statement:
Here I have used a subquery to select only the author record information, if the author's record has a state column equal to "CA." I have named the set returned from this subquery with a table alias of "a." I can then use this alias elsewhere in the T-SQL statement to refer to the columns from the subquery by prefixing them with an "a", as I did in the "ON" clause of the "JOIN" criteria. Sometimes using a subquery in the FROM clause reduces the size of the set that needs to be joined. Reducing the number of records that have to be joined enhances the performance of joining rows, and therefore speeds up the overall execution of a query.
Here is an example where I used a subquery in the FROM clause of an UPDATE statement:
Here I created a table named "x," that has four rows. Then I proceeded to update the rows where "i" was greater than 2 with the max value in column "a". I used a subquery in the FROM clause of the UPDATE statement to identity the max value of column "a."
Use of a Subquery in the HAVING clause
In the following example, I used a subquery to find the number of books a publisher has published where the publisher is not located in the state of California. To accomplish this I used a subquery in a HAVING clause. Here is my code:
Here my subquery returns the pub_name values for all publishers that have a state value not equal to "CA." The HAVING condition then checks to see if the pub_name is in the set returned by my subquery.
(Taken From Databasejournal article by Gregory A. Larsen)
A subquery is a SELECT statement that is nested within another T-SQL statement. A subquery SELECT statement if executed independently of the T-SQL statement, in which it is nested, will return a result set. Meaning a subquery SELECT statement can standalone and is not depended on the statement in which it is nested. A subquery SELECT statement can return any number of values, and can be found in, the column list of a SELECT statement, a FROM, GROUP BY, HAVING, and/or ORDER BY clauses of a T-SQL statement. A Subquery can also be used as a parameter to a function call. Basically a subquery can be used anywhere an expression can be used.
Use of a Subquery in the Column List of a SELECT Statement
Suppose you would like to see the last OrderID and the OrderDate for the last order that was shipped to Paris. Along with that information, say you would also like to see the OrderDate for the last order shipped regardless of the ShipCity. In addition to this, you would also like to calculate the difference in days between the two different OrderDates. Here is my T-SQL SELECT statement to accomplish this:
select top 1 OrderId,convert(char(10),
OrderDate,121) Last_Paris_Order,
(select convert(char(10),max(OrderDate),121) from
Northwind.dbo.Orders) Last_OrderDate,
datediff(dd,OrderDate,
(select Max(OrderDate)from Northwind.dbo.Orders)) Day_Diff
from Northwind.dbo.Orders
where ShipCity = 'Paris'
order by OrderDate desc
OrderDate,121) Last_Paris_Order,
(select convert(char(10),max(OrderDate),121) from
Northwind.dbo.Orders) Last_OrderDate,
datediff(dd,OrderDate,
(select Max(OrderDate)from Northwind.dbo.Orders)) Day_Diff
from Northwind.dbo.Orders
where ShipCity = 'Paris'
order by OrderDate desc
The above code contains two subqueries. The first subquery gets the OrderDate for the last order shipped regardless of ShipCity, and the second subquery calculates the number of days between the two different OrderDates. Here I used the first subquery to return a column value in the final result set. The second subquery was used as a parameter in a function call. This subquery passed the "max(OrderDate)" date to the DATEDIFF function.
Use of a Subquery in the WHERE clause
A subquery can be used to control the records returned from a SELECT by controlling which records pass the conditions of a WHERE clause. In this case the results of the subquery would be used on one side of a WHERE clause condition. Here is an example:select distinct country from Northwind.dbo.Customers
where country not in (select distinct country from Northwind.dbo.Suppliers)
Here I have returned a list of countries where customers live, but there is no supplier located in that country. I suppose if you where trying to provide better delivery time to customers, then you might target these countries to look for additional suppliers.
Suppose a company would like to do some targeted marketing. This targeted marketing would contact customers in the country with the fewest number of orders. It is hoped that this targeted marketing will increase the overall sales in the targeted country. Here is an example that uses a subquery to return the customer contact information for the country with the fewest number of orders:
A subquery can be used to control the records returned from a SELECT by controlling which records pass the conditions of a WHERE clause. In this case the results of the subquery would be used on one side of a WHERE clause condition. Here is an example:select distinct country from Northwind.dbo.Customers
where country not in (select distinct country from Northwind.dbo.Suppliers)
Here I have returned a list of countries where customers live, but there is no supplier located in that country. I suppose if you where trying to provide better delivery time to customers, then you might target these countries to look for additional suppliers.
Suppose a company would like to do some targeted marketing. This targeted marketing would contact customers in the country with the fewest number of orders. It is hoped that this targeted marketing will increase the overall sales in the targeted country. Here is an example that uses a subquery to return the customer contact information for the country with the fewest number of orders:
select Country,CompanyName, ContactName, ContactTitle, Phone
from Northwind.dbo.Customers
where country =
(select top 1 country
from Northwind.dbo.Customers C
join
Northwind.dbo.Orders O
on C.CustomerId = O.CustomerID
group by country
order by count(*))
from Northwind.dbo.Customers
where country =
(select top 1 country
from Northwind.dbo.Customers C
join
Northwind.dbo.Orders O
on C.CustomerId = O.CustomerID
group by country
order by count(*))
Here I have written a subquery that joins the Customer and Orders Tables to determine the total number of orders for each country. The subquery uses the "TOP 1" clause to return the country with the fewest number of orders. The country with the fewest number of orders is then used in the WHERE clause to determine which Customer Information will be displayed.
Use of a Subquery in the FROM clause
The FROM clause normally identifies the tables used in the T-SQL statement. You can think of each of the tables identified in the FROM clause as a set of records. Well, a subquery is just a set of records, and therefore can be used in the FROM clause just like a table. Here is an example where a subquery is used in the FROM clause of a SELECT statement:
select au_lname, au_fname, title from
(select au_lname, au_fname, au_id from pubs.dbo.authors
where state = 'CA') as a
join
pubs.dbo.titleauthor ta on a.au_id=ta.au_id
join
pubs.dbo.titles t on ta.title_id = t.title_id
(select au_lname, au_fname, au_id from pubs.dbo.authors
where state = 'CA') as a
join
pubs.dbo.titleauthor ta on a.au_id=ta.au_id
join
pubs.dbo.titles t on ta.title_id = t.title_id
Here I have used a subquery to select only the author record information, if the author's record has a state column equal to "CA." I have named the set returned from this subquery with a table alias of "a." I can then use this alias elsewhere in the T-SQL statement to refer to the columns from the subquery by prefixing them with an "a", as I did in the "ON" clause of the "JOIN" criteria. Sometimes using a subquery in the FROM clause reduces the size of the set that needs to be joined. Reducing the number of records that have to be joined enhances the performance of joining rows, and therefore speeds up the overall execution of a query.
Here is an example where I used a subquery in the FROM clause of an UPDATE statement:
set nocount on
create table x(i int identity,
a char(1))
insert into x values ('a')
insert into x values ('b')
insert into x values ('c')
insert into x values ('d')
select * from x
update x
set a = b.a
from (select max(a) as a from x) b
where i > 2
select * from x
drop table x
create table x(i int identity,
a char(1))
insert into x values ('a')
insert into x values ('b')
insert into x values ('c')
insert into x values ('d')
select * from x
update x
set a = b.a
from (select max(a) as a from x) b
where i > 2
select * from x
drop table x
Here I created a table named "x," that has four rows. Then I proceeded to update the rows where "i" was greater than 2 with the max value in column "a". I used a subquery in the FROM clause of the UPDATE statement to identity the max value of column "a."
Use of a Subquery in the HAVING clause
In the following example, I used a subquery to find the number of books a publisher has published where the publisher is not located in the state of California. To accomplish this I used a subquery in a HAVING clause. Here is my code:
select pub_name, count(*) bookcnt
from pubs.dbo.titles t
join
pubs.dbo.publishers p
on t.pub_id = p.pub_id
group by pub_name
having p.pub_name in
(select pub_name from pubs.dbo.publishers where state <> 'CA')
from pubs.dbo.titles t
join
pubs.dbo.publishers p
on t.pub_id = p.pub_id
group by pub_name
having p.pub_name in
(select pub_name from pubs.dbo.publishers where state <> 'CA')
Here my subquery returns the pub_name values for all publishers that have a state value not equal to "CA." The HAVING condition then checks to see if the pub_name is in the set returned by my subquery.
(Taken From Databasejournal article by Gregory A. Larsen)
Mirror of My Blog!
Hi guys
Find my another Blog address as spaces.msn.com
http://spaces.msn.com/vickysqlserver/
You will find whole lot of information regarding SQL Server 2005/2000
Thanks to all for there support.
Chill.....
Find my another Blog address as spaces.msn.com
http://spaces.msn.com/vickysqlserver/
You will find whole lot of information regarding SQL Server 2005/2000
Thanks to all for there support.
Chill.....
Friday, April 14, 2006
Welcome to Shekhar's Space For SQLServer
Shri Ganeshai Namah
vakratu.nDa mahaakaaya koTisuuryasamaprabha nirvighnaM kuru me deva sarvakaaryeshhu sarvadaa
Today i gonna list my first blog entry.
So i thought its good to start with Ganesha Sloka.Its used in India to seek blessing of Lord Ganesha.
Lets share our knowledge through out the world.
I would like your comments about the Blog , new entries , and materials related to the SQL server 2K/2K5.
Ok now I am ending todays work and starting a new chapter in Blogging.
Well thanks to all for there support and happy blogging.
II Meaning of Shree Ganesha Shloka II
O God Ganesha (large bodied with a large belly), radiant as millions of Suns, Please, remove obstacles in all of my tasks all the time
Subscribe to:
Comments (Atom)